data- driven подход к управлению надежностью систем
Site
Reliability
Engineering
Старт: дата уточняется
Консультация с менеджером
Обсудим ваши цели и текущие знания.
Обучение платное
Обучение платное

О курсе
Мы проводим этот практикум для инженеров в десятый раз. Программа сформирована с участием SRE-инженеров из зарубежных и российских компаний, таких как: Google, Booking, Databricks, TangoMe, Яндекс, Ecommpay, Финам.
На время обучения вы станете SRE для сервиса покупки билетов в кинотеатр. Решая предложенные кейсы, вы получите представление, чем занимается SRE в реальности.
На время обучения вы станете SRE для сервиса покупки билетов в кинотеатр. Решая предложенные кейсы, вы получите представление, чем занимается SRE в реальности.
На интенсиве вы:
научитесь быстро поднимать продакшн силами команды;
поймете, какие метрики собирать и как это делать правильно;
узнаете, как решать конкретные проблемы, связанные с надежностью сервиса;
внедрите правки прямо в прод;
узнаете, как снизить ущерб от отказов в будущем.
Кому полезно
ЛЮДЯМ
SRE-инженером может стать как инженер эксплуатации, так и разработчик.
Во время обучения вы будете много практиковаться, а полученные навыки и знания можно адаптировать и внедрить в любую сферу.
Во время обучения вы будете много практиковаться, а полученные навыки и знания можно адаптировать и внедрить в любую сферу.
БИЗНЕСУ
SRE решает те же проблемы, что и DevOps: увеличивает скорость выхода новых фич и налаживает процессы в команде. Но основная задача SRE – обеспечить стабильность и надежность работы сервисов, исключая ситуации, когда пользователи жалуются на сбои, а у инженеров «графики зеленые».
На курсе сотрудники получат представление о задачах специалиста по SRE в компании, изучат практики повышения надежности. Новая культура производства приведет к следующим изменениям:
Результаты внедрения SRE-подхода
Снижение процента отказов сервиса
Повышение скорости реагирования на отказы
Снижение рисков при выкате новых фич
Увеличение скорости разработки




SRE подход — это методология работы с цифровыми продуктами. Её задача — через улучшение процессов и автоматизацию уменьшить время простоя и количество ошибок сервиса, делая бизнес, основанный на информационных системах, более предсказуемым и устойчивым.
Чтобы внедрить SRE предстоит:
определить команды разработки, где будет внедряться SRE. Экономический эффект будет максимальным, если эти команды отвечают за решения, генерирующие основную выручку;
обучить лидеров и сотрудников этих команд подходу и инструментам SRE;
сформировать процессы улучшения этих метрик.
выработать политику улучшения этих метрик (подход к мониторингу, бюджет ошибок, соответствующую автоматизацию);
определить метрики, которые будет улучшать SRE, и научиться их замерять;
В результате обучения
Могу настроить:
мониторинг SRE-метрик (SLO, SLI, error budget) для своего сервиса. Понимаю как эти метрики выбрать;
мониторинг SRE-инфраструктурных сервисов. Умею опознавать и решать проблемы с инфраструктурой;
alerting и healthcheck;
разные методы деплоймента, знаю какие инструменты для этого существуют.
мониторинг SRE-инфраструктурных сервисов. Умею опознавать и решать проблемы с инфраструктурой;
alerting и healthcheck;
разные методы деплоймента, знаю какие инструменты для этого существуют.
пожарную команду в случае инцидента, раздать роли коллегам и выступить лидером. Знаю, какие инцидент сервисы существуют;
надежные коммуникации между сервисами retry, timeout, circuit breaker.
надежные коммуникации между сервисами retry, timeout, circuit breaker.
Могу организовать:

Вы сможете составить план действий по внедрению SRE подхода в своей компании. Поймете, как коммуницировать с бизнесом, с коллегами в случае аварии, как принимать сервисы на поддержку.
Условия получения номерного сертификата:
- Все сданные домашние задания до конца курса
- Участие и работа в 3-х практикумах онлайн
При пропуске практикума и домашних заданий выдается свидетельство

SRE: data-driven
Как проходит курс
- Теоретические лекцииКаждый понедельник будут открываться видеолекции с теорией для самостоятельного изучения. Полученные знания вы сможете закрепить на практических занятиях по субботам и задать вопросы на встречах со спикерами в течении недели. На изучение теории нужно выделять 2-3 часа в неделю.
- Встречи со спикерами и ответы на вопросыНа еженедельных встречах вы сможете получить ответы на свои вопросы и предметнее обсудить применение инструментов SRE в вашей компании.
- Практикумы
На субботних практикумах вы сможете закрепить теорию на стендах, работая над практическими кейсами. Вас ждут 4-5 часов насыщенной работы в командах под руководством наставников нашего курса. Это прекрасная возможность применить свои знания на практике и получить ценный опыт работы в команде - Командная работаНа первой встрече курса вы объединитесь в команды, чтобы познакомиться, распределить роли и научиться работать в коллективе. Этот принципа важен, потому что вам необходимо научиться выстраивать командное взаимодействие в соответствии с принципами SRE.
Строим:
Наш учебный сайт состоит из нескольких микросервисов. Он агрегирует данные о сеансах, ценах и свободных местах со всех кинотеатров, показывает анонсы фильмов, дает выбрать кинотеатр, сеанс, зал и место, забронировать и оплатить билеты.
Мы сформулируем показатели SLO, SLI, SLA для этого сайта, разработаем архитектуру и инфраструктуру, которая их обеспечит, настроим мониторинг и алертинг.
Мы сформулируем показатели SLO, SLI, SLA для этого сайта, разработаем архитектуру и инфраструктуру, которая их обеспечит, настроим мониторинг и алертинг.
Внутренние и внешние факторы начинают «портить» SLO
Ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки приводят к тому, что SLO ухудшаются.
Разбираем устойчивость, error budget, практику тестирования, управление прерываниями и операционной нагрузкой.
Ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки приводят к тому, что SLO ухудшаются.
Разбираем устойчивость, error budget, практику тестирования, управление прерываниями и операционной нагрузкой.
Ломаем:
Чиним:
incident response
Произошла авария. Сервис обработки платежей лег. Как действовать, чтобы восстановить работоспособность в минимальные сроки?
Организуем работу группы по ликвидации аварии: подключение коллег, оповещение интересантов (stakeholders), выстраивание приоритетов. Тренируемся работать под давлением в условиях предельно ограниченного времени.
Произошла авария. Сервис обработки платежей лег. Как действовать, чтобы восстановить работоспособность в минимальные сроки?
Организуем работу группы по ликвидации аварии: подключение коллег, оповещение интересантов (stakeholders), выстраивание приоритетов. Тренируемся работать под давлением в условиях предельно ограниченного времени.
Cмотрим на сайт и инциденты с точки зрения SRE
Разбираем подход к сайту с точки зрения SRE. Анализируем инциденты (причины возникновения, ход устранения). Принимаем решение по их дальнейшему предотвращению: улучшаем мониторинг, меняем архитектуру, подход к разработке и эксплуатации, регламенты. Автоматизируем процессы.
Разбираем подход к сайту с точки зрения SRE. Анализируем инциденты (причины возникновения, ход устранения). Принимаем решение по их дальнейшему предотвращению: улучшаем мониторинг, меняем архитектуру, подход к разработке и эксплуатации, регламенты. Автоматизируем процессы.
Изучаем:
Расписание встреч
Обсудим цели и задачи курса, а также расскажем что такое SRE, распределим на команды.
Открытие 2 теоретических тем:
Тема 1: Мониторинг
Тема 2: Теория SRE
Открытие 2 теоретических тем:
Тема 1: Мониторинг
- Зачем нужен мониторинг
- Перцентили
- Alerting
- Observability
Тема 2: Теория SRE
- SLO, SLI, SLA
- Durability
- Error budget
Практика: Делаем базовый дашборд и настраиваем необходимые алерты
Практика: Добавляем на дашборд SLO/SLI + алерты
Практика: Первая нагрузка системы
Решение 1 кейса: зависимость downstream.
В большой системе существует много взаимозависимых сервисов, и не всегда они работают одинаково хорошо. Особенно обидно, когда с вашим сервисом порядок, а соседний, от которого вы зависите, периодически уходит в down.
Учебный проект окажется именно в таких условиях, а вы сделаете так, чтобы он все равно выдавал качество на максимально возможном уровне.
Практика: Добавляем на дашборд SLO/SLI + алерты
Практика: Первая нагрузка системы
Решение 1 кейса: зависимость downstream.
В большой системе существует много взаимозависимых сервисов, и не всегда они работают одинаково хорошо. Особенно обидно, когда с вашим сервисом порядок, а соседний, от которого вы зависите, периодически уходит в down.
Учебный проект окажется именно в таких условиях, а вы сделаете так, чтобы он все равно выдавал качество на максимально возможном уровне.
AMA-сессия и ответы на вопросы
Открывается доступ к 2-му теоретическому модулю:
Решение проблем с окружением и архитектурой
Второй модуль построен вокруг решения двух кейсов: зависимость upstream и проблемы с архитектурой. Спикеры расскажут про управление инцидентами, правила для пожарной команды и работу с постмортерами (post mortem) и дадут шаблоны, которые вы сможете использовать в своей команде.
Тема 3: Управление инцидентами
Тема 4: Инструменты варрума и алерт менеджмента.
Вest practiсe других компаний в организации инцидент-менеджмента.
Открывается доступ к 2-му теоретическому модулю:
Решение проблем с окружением и архитектурой
Второй модуль построен вокруг решения двух кейсов: зависимость upstream и проблемы с архитектурой. Спикеры расскажут про управление инцидентами, правила для пожарной команды и работу с постмортерами (post mortem) и дадут шаблоны, которые вы сможете использовать в своей команде.
Тема 3: Управление инцидентами
- Resiliencе Engineering
- Как выстраивается пожарная бригада
- Насколько ваша команда эффективна в инциденте
- 7 правил для лидера инцидента
- 5 правил для пожарного
- HiPPO — highest paid person's opinion. Communications Leader
Тема 4: Инструменты варрума и алерт менеджмента.
Вest practiсe других компаний в организации инцидент-менеджмента.
Решение 2 кейса: зависимость upstream.
Одно дело, когда вы зависите от сервиса с низким SLO. Другое дело, когда ваш сервис является таковым для других частей системы. Так бывает, если критерии оценки не согласованы: например, вы отвечаете на запрос в течение секунды и считаете это успехом, а зависимый сервис ждёт всего 500 мск и уходит с ошибкой.
В кейсе обсудим важность согласования метрик и научимся смотреть на качество глазами клиента.
Решение 3 кейса: проблемы с базой данных.
База данных тоже может быть источником проблем. Например, если не следить за replication relay, то реплика устареет и приложение будет отдавать старые данные. Причём дебажить такие случаи особенно сложно: сейчас данные рассогласованы, а через несколько секунд уже нет, и в чём причина проблемы — непонятно.
Через кейс вы прочувствуете всю боль дебага и узнаете, как предотвращать подобные проблемы.
Практика работы с постмортемами
Практика: Пишем постмортем по предыдущему кейсу и разбираем его со спикерами.
Одно дело, когда вы зависите от сервиса с низким SLO. Другое дело, когда ваш сервис является таковым для других частей системы. Так бывает, если критерии оценки не согласованы: например, вы отвечаете на запрос в течение секунды и считаете это успехом, а зависимый сервис ждёт всего 500 мск и уходит с ошибкой.
В кейсе обсудим важность согласования метрик и научимся смотреть на качество глазами клиента.
Решение 3 кейса: проблемы с базой данных.
База данных тоже может быть источником проблем. Например, если не следить за replication relay, то реплика устареет и приложение будет отдавать старые данные. Причём дебажить такие случаи особенно сложно: сейчас данные рассогласованы, а через несколько секунд уже нет, и в чём причина проблемы — непонятно.
Через кейс вы прочувствуете всю боль дебага и узнаете, как предотвращать подобные проблемы.
Практика работы с постмортемами
Практика: Пишем постмортем по предыдущему кейсу и разбираем его со спикерами.
AMA-сессия и ответы на вопросы по предыдущим темам.
Открывается доступ к 3-му теоретическому модулю:
Traffic shielding и канареечные релизы
В третьем модуле мы разберем кейс, посвященный проблеме с окружением, а также поэтапно разберем, как внедрять SRE в компании и узнаем опыт компаний, в которых работают спикеры курса.
Тема 5: Health Checking
Тема 6: Способы деплоймента
Тема 7: SRE онбординг проекта
В крупных компаниях нередко формируют отдельную команду SRE, которая берёт на поддержку сервисы других отделов. Но не каждый сервис готов к тому, чтобы его можно было взять на поддержку. Расскажем, каким требованиям он должен отвечать. А также спикеры поделяться опытом, как у них проходило внедрение SRE и на какие грабли они наступали.
Открывается доступ к 3-му теоретическому модулю:
Traffic shielding и канареечные релизы
В третьем модуле мы разберем кейс, посвященный проблеме с окружением, а также поэтапно разберем, как внедрять SRE в компании и узнаем опыт компаний, в которых работают спикеры курса.
Тема 5: Health Checking
- Health Check в Kubernetes
- Жив ли наш сервис?
- Exec probes
- InitialDelaySeconds
- Secondary Health Port
- Sidecar Health Server
- Headless Probe
- Hardware Probe
Тема 6: Способы деплоймента
Тема 7: SRE онбординг проекта
В крупных компаниях нередко формируют отдельную команду SRE, которая берёт на поддержку сервисы других отделов. Но не каждый сервис готов к тому, чтобы его можно было взять на поддержку. Расскажем, каким требованиям он должен отвечать. А также спикеры поделяться опытом, как у них проходило внедрение SRE и на какие грабли они наступали.
Решение 4 кейса: проблема с окружением, билеты купить невозможно.
Задача Healthcheck — обнаружить неработающий сервис и заблокировать трафик к нему. И если вы думаете, что для этого достаточно сделать рутом запрос к сервису и получить ответ, то вы ошибаетесь: даже если сервис ответит, это не гарантирует его работоспособность — проблемы могут быть в окружении.
Через этот кейс вы научитесь настраивать корректный Healthcheck и не пускать трафик туда, где он не может быть обработан.
Подведение итогов
Задача Healthcheck — обнаружить неработающий сервис и заблокировать трафик к нему. И если вы думаете, что для этого достаточно сделать рутом запрос к сервису и получить ответ, то вы ошибаетесь: даже если сервис ответит, это не гарантирует его работоспособность — проблемы могут быть в окружении.
Через этот кейс вы научитесь настраивать корректный Healthcheck и не пускать трафик туда, где он не может быть обработан.
Подведение итогов
Подготовка
В процессе решения кейсов вам необходимо будет писать код на Python, если вы кодить не умеете, мы определим вас в команду, где эта экспертиза будет.
Также необходимо знать Linux и иметь навыки работы в кластере Kubernetes.
Также необходимо знать Linux и иметь навыки работы в кластере Kubernetes.

Спикеры курса


Курс основан на реальном опыте специалистов из крупных российских и зарубежных компаний. Программа дорабатывалась с каждым последующим интенсивом. Над данным интенсивом работали:
Павел Селиванов
Архитектор Yandex Cloud
— Десятки выстроенных инфраструктур и сотни написанных пайплайнов CI/CD
— Certified Kubernetes Administrator
— Автор нескольких курсов по Kubernetes и DevOps
— Регулярный докладчик на Российских и международных IT-конференциях
Записи выступлений:
DevOpsDays Moscow
DevOpsConf 2019
— Certified Kubernetes Administrator
— Автор нескольких курсов по Kubernetes и DevOps
— Регулярный докладчик на Российских и международных IT-конференциях
Записи выступлений:
DevOpsDays Moscow
DevOpsConf 2019
Владимир Федорков
Эксперт в области высоких нагрузок
— Спикер Highload++ 2022
— Десятки успешных проектов по подъему нагрузки в США, Европе и России
— Серьезный опыт кризис-менеджмента и ведения инцидентов
— Регулярный докладчик на конференциях и митах
Записи выступлений:
Highload++ 2021
Big Data Days 2021
— Десятки успешных проектов по подъему нагрузки в США, Европе и России
— Серьезный опыт кризис-менеджмента и ведения инцидентов
— Регулярный докладчик на конференциях и митах
Записи выступлений:
Highload++ 2021
Big Data Days 2021
Максим Гусев
SRE Dodo Engineering
— Тысячи выстроенных пайплайнов CI/CD
— Более 100 инсталляций Kubernetes в продакшен
— Автор нескольких курсов по DevOps и его внедрению
— Более 100 инсталляций Kubernetes в продакшен
— Автор нескольких курсов по DevOps и его внедрению
Сергей Бухаров
Head of SRE Process в Dodo Engineering
— .NET и Node.js разработчик
— Технический лидер Dodo Engineering, внедрение культуры SRE
— Спикер конференций HighLoad, DevOps Live, DevOops и Podlodka Crew
Записи выступлений:
Доклад на HighLoad++
— Технический лидер Dodo Engineering, внедрение культуры SRE
— Спикер конференций HighLoad, DevOps Live, DevOops и Podlodka Crew
Записи выступлений:
Доклад на HighLoad++
Павел Лакосников
Team Lead команды SLA в Авито
– Более 10 лет в разработке
– Фанат метрик
– Регулярный докладчик на конференциях и митапах
Записи выступлений:
Highload++ 2023
Highload++ 2022
PHP Russia 2021
– Фанат метрик
– Регулярный докладчик на конференциях и митапах
Записи выступлений:
Highload++ 2023
Highload++ 2022
PHP Russia 2021
Подарить курс
Заполните форму — наши менеджеры свяжутся с вами, помогут оплатить курс со скидкой 10% и вручат подарок счастливчику.

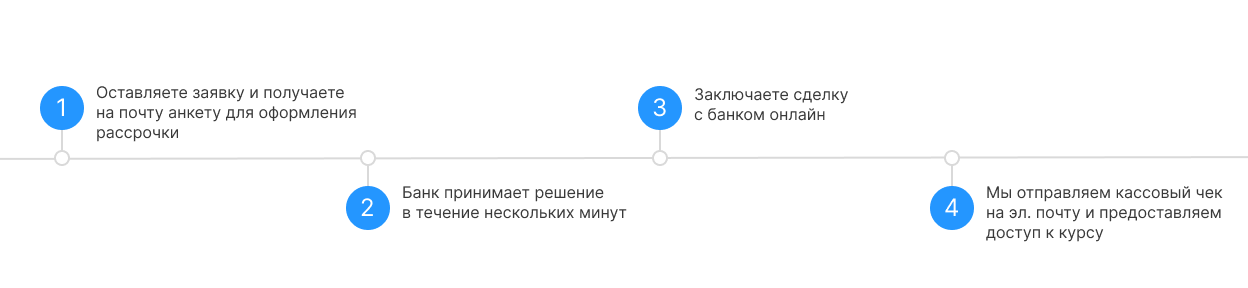
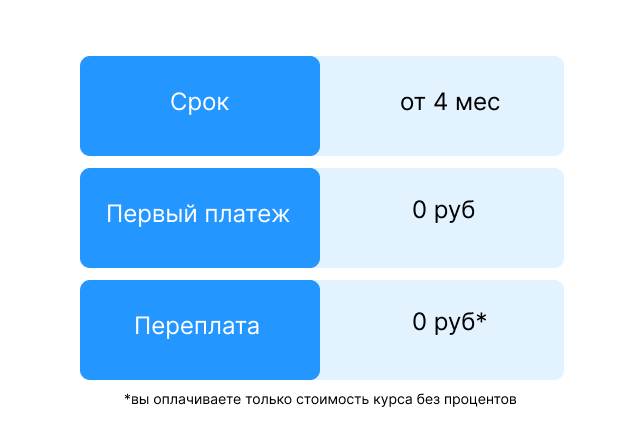
Рассрочка
только для физических лиц
Условия рассрочки:
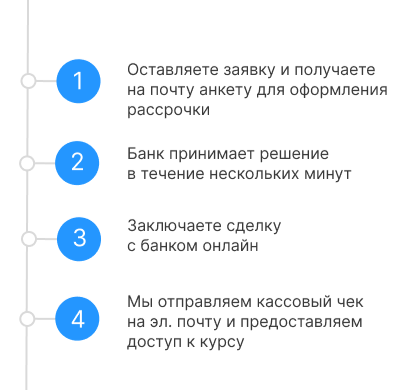

Процесс оформления:


Начать учиться
Лекции по метрикам
SLO, SLI, SLA
SLO, SLI, SLA
Zoom-трансляция и AMA-cессии
Техподдержка и разбор ошибок
Работа в группах с куратором или спикером
Практика на микросервисном приложении
Доступ к материалам на 2 года
Видео
с теорией
с теорией
бесплатно
Бесплатные лекции
Участник
22 500 ₽
единовременно
/
90 000 ₽
Zoom-трансляция и AMA-cессии
Техподдержка и разбор ошибок
Работа в группах с куратором или спикером
Практика на микросервисном приложении
Доступ к материалам на 2 года
Видео
с теорией
с теорией
Оплатить участие
в курсе по SRE
Оплатить как юр.лицо
Мы свяжемся с вами, ответим на вопросы и отправим счёт
Оставить заявку на оплату с зарубежной карты
Мы свяжемся с вами и вышлем ссылку для оплаты
Заявка на команду
Отзывы студентов

Отзывы студентов
Менеджер по продажам
Альберт Матюхин
Нужна консультация?
Обсудим ваши цели и ответим на вопросы
Отправляя форму, я соглашаюсь с Политикой Конфиденциальности Слёрм и предоставляю Согласие на обработку персональных данных и аудио- и видеорелиз
Комплект
Комплект видеокурсов
Выгода 25 000 ₽
45 000 ₽
Поток
Для SRE-инженеров, которые хотят взять под контроль состояние системы
SRE: Observability




Купить комплект
SRE + SRE:Observability + Мониторинг в Grafana

Углубленный курс о продвинутых SRE- метриках. Вы узнаете, как выбрать технические метрики оценки надежности для своего сервиса SLO и SLI, научитесь их отслеживать, а также увидите вживую, как они деградируют.
SRE Observability
это может быть интересно