
Материал подготовлен на основе перевода оригинальной статьи в блоге Confluent, автор – Dave Klein.
kcat
Начнём с этого потрясающего инструмента.
kcat (ранее — kafkacat) — это быстрая и гибкая утилита командной строки для работы с топиками (создания, удаления), отправки и получения данных в/из Kafka и т. д. Разработчик — Магнус Эденхилл (Magnus Edenhill), создатель библиотеки librdkafka C/C++ для Kafka. Это отличный инструмент для быстрого создания и потребления данных из топика. Одна команда может делать и то, и другое, в зависимости от контекста. Например:
$ ~ echo "Hello World" | kafkacat -b localhost:29092 -t hello-topic
% Auto-selecting Producer mode (use -P or -C to override)
Мы отправили данные в stdout с помощью echo и передали их в kcat. Нам понадобилось два простых флага: -b для указания брокера и -t для указания названия целевого топика. kcat понимает, что мы посылаем ему данные, и переходит в режим продюсера. Вычитать данные из топика можно точно такой же командой:
$ ~ kafkacat -b localhost:29092 -t hello-topic
% Auto-selecting Consumer mode (use -P or -C to override)
Hello World
% Reached end of topic hello-topic [0] at offset 1
Если мы хотим отправить запись с ключом, нужно просто использовать разделитель и флаг -K. В этом случае используем двоеточие:
$ ~ echo "123:Jane Smith" | kafkacat -b localhost:29092 -t customers -K:
% Auto-selecting Producer mode (use -P or -C to override)
И снова та же команда считает запись из топика:
$ ~ kafkacat -b localhost:29092 -t customers -K:
% Auto-selecting Consumer mode (use -P or -C to override)
123:Jane Smith
% Reached end of topic customers [0] at offset 1
Можно не указывать флаг -K при чтении, если нам требуется только значение:
$ ~ kafkacat -b localhost:29092 -t customers
% Auto-selecting Consumer mode (use -P or -C to override)
Jane Smith
% Reached end of topic customers [0] at offset 1
Передавая данные из stdout в kcat, мы запускаем продюсер, отправляем данные и закрываем продюсер. Если мы хотим, чтобы продюсер продолжил работу, указываем флаг -P, как указано в подсказке auto-selecting.
Консьюмер продолжит работу, как сделал бы kafka-console-consumer. Чтобы получить данные из топика и сразу выйти, используем флаг -e.
Чтобы получить данные в формате Avro, используем флаг -s: для всей записи (-s avro), для ключа (-s key=avro) или только для значения (-s value=avro). Вот пример использования топика movies из популярного руководства по оценке фильмов:
$ ~ kafkacat -C -b localhost:29092 -t movies -s value=avro -r http://localhost:8081
------------------------------------------------------
{"id": 294, "title": "Die Hard", "release_year": 1988}
{"id": 354, "title": "Tree of Life", "release_year": 2011}
{"id": 782, "title": "A Walk in the Clouds", "release_year": 1995}
{"id": 128, "title": "The Big Lebowski", "release_year": 1998}
{"id": 780, "title": "Super Mario Bros.", "release_year": 1993}
Это на самом деле мощный инструмент, флагов там намного больше. Запустите kafkacat -h, чтобы получить полный список. Больше примеров использования kcat читайте в блоге Robin Moffatt.
В kcat недостаёт возможности создавать данные в формате Avro. Мы уже видели, что получать Avro можно с помощью Confluent Schema Registry, а отправлять нельзя. Поэтому переходим к следующему инструменту.
Confluent REST Proxy
Confluent REST Proxy — это клиент HTTP Kafka со множеством функций. С его помощью можно предоставлять поддержку Kafka в приложениях на языках, для которых нет нативного клиента Kafka. Это его основное применение, но есть и другие. Например, он создаёт данные Avro в топике Kafka:
$ ~ curl -X POST \
-H "Content-Type: application/vnd.kafka.avro.v2+json" \
-H "Accept: application/vnd.kafka.v2+json" \
--data @newMovieData.json "http://localhost:8082/topics/movies"
------------------------------------------------------------------------------
{"offsets":[{"partition":0,"offset":5,"error_code":null,"error":null}],"key_schema_id":null,"value_schema_id":3}
REST Proxy входит в Confluent Platform и предоставляется по лицензии Confluent Community License, но может использоваться отдельно с любым кластером Kafka. Он действительно на многое способен — читайте документацию.
Как видите, REST Proxy можно использовать из командной строки с curl или чем-то подобным. Ещё его можно использовать с такими инструментами, как Postman, для создания удобного пользовательского интерфейса Kafka.
Пример создания данных в топике с помощью Postman (заголовки Content-Type и Accept заданы на вкладке Headers):
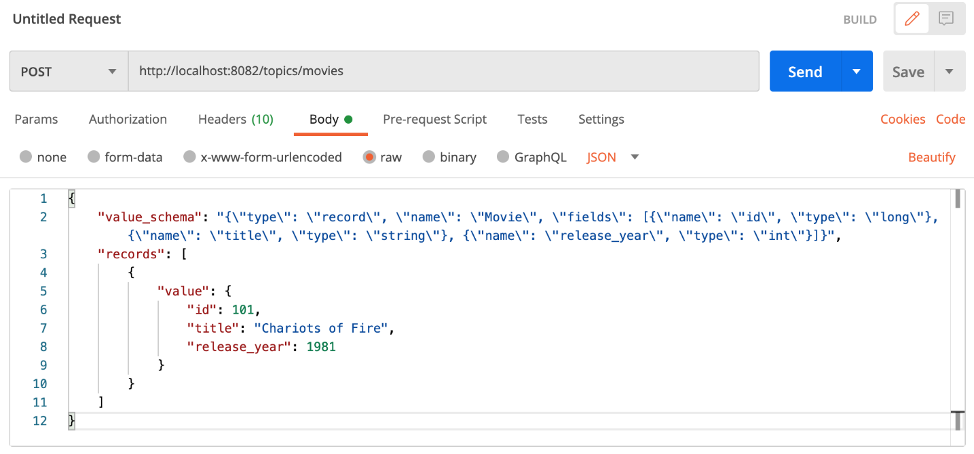
Как мы видели в примерах с curl и Postman, REST Proxy требует передавать схему для сообщений Avro с каждым запросом на создание. С Postman или подобным инструментом, который позволяет создавать библиотеку сохранённых запросов, этими процессами будет проще управлять.
Чтобы потреблять данные из топика с помощью REST Proxy, мы сначала создаём консьюмера в группе консьюмеров, а потом подписываемся на топик (или топики) и, наконец, получаем записи. Переключаемся обратно на curl, так мы сможем увидеть все необходимые элементы сразу.
Сначала выполняем POST эндпоинте консьюмера, указав имя нашей группы консьюмеров. В этом запросе POST мы передадим имя нового инстанса консьюмера, формат внутренних данных (у нас это Avro) и значение auto.offset.reset.
$ ~ curl -X POST -H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"name": "movie_consumer_instance", "format": "avro", "auto.offset.reset": "earliest"}' \
http://localhost:8082/consumers/movie_consumers
------------------------------------------------------------------------------
{"instance_id":"movie_consumer_instance","base_uri":"http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance"}
Вернётся instance id и базовый URI для только что созданного инстанса консьюмера. Укажем этот URI, чтобы подписаться на топик, указав конечную точку subscription.
$ ~ curl -X POST -H "Content-Type: application/vnd.kafka.v2+json" --data '{"topics":["movies"]}' \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/subscription
Вернётся только ответ 204. Теперь можно выполнить запрос GET эндпоинту records по тому же URI, чтобы получить записи.
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records
----------------------------------------------------------------------
[{"topic":"movies","key":null,"value":{"id": 294, "title": "Die Hard", "release_year": 1988},"partition":0,"offset":0},
{"topic":"movies","key":null,"value":{"id": 354, "title": "Tree of Life", "release_year": 2011},"partition":0,"offset":1},{"topic":"movies","key":null,"value":{"id": 782, "title": "A Walk in the Clouds", "release_year": 1995},"partition":0,"offset":2},{"topic":"movies","key":null,"value":{"id": 128, "title": "The Big Lebowski", "release_year": 1998},"partition":0,"offset":3},{"topic":"movies","key":null,"value":{"id": 780, "title": "Super Mario Bros.", "release_year": 1993},"partition":0,"offset":4},{"topic":"movies","key":null,"value":{"id":101,"title":"Chariots of Fire","release_year":1981},"partition":0,"offset":5}]
Созданный консьюмер останется, так что мы сможем выполнить тот же запрос GET в любое время, чтобы проверить новые данные. Если этот консьюмер больше не нужен, можно его удалить с помощью DELETE и базового URI.
$ ~ curl -X DELETE -H "Content-Type: application/vnd.kafka.v2+json" \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance
Простые запросы GET позволяют получать информацию о brokers, topics и partitions.
$ ~ curl "http://localhost:8082/brokers"
$ ~ curl "http://localhost:8082/topics"
$ ~ curl "http://localhost:8082/topics/movies"
$ ~ curl "http://localhost:8082/topics/movies/partitions"
Эти запросы возвращают много данных JSON, так что здесь мы их приводить не будем, чтобы не занимать место. И это подводит нас к следующему инструменту.
jq: утилита для работы с JSON из командной строки
jq используется не только с Kafka. Это очень полезный инструмент, если мы работаем с другими утилитами командной строки, которые возвращают данные JSON. С помощью jq можно форматировать, обрабатывать и извлекать данные из выходных данных других программ в формате JSON. Инструкции по загрузке и установке jq см. на GitHub. Там же вы найдете ссылки на инструкции и другие ресурсы.
Вернёмся к выходным данным REST Proxy в запросе GET к консьюмеру. Это не самый большой BLOB в формате JSON, но всё же читать его неудобно. Попробуем ещё раз, на этот раз передав выходные данные в jq:
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \
http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records | jq
[
{
"topic": "movies",
"key": null,
"value": {
"id": 294,
"title": "Die Hard",
"release_year": 1988
},
"partition": 0,
"offset": 0
},
{
"topic": "movies",
"key": null,
"value": {
"id": 354,
"title": "Tree of Life",
"release_year": 2011
},
"partition": 0,
"offset": 1
},
{
"topic": "movies",
"key": null,
"value": {
"id": 782,
"title": "A Walk in the Clouds",
"release_year": 1995
},
"partition": 0,
"offset": 2
},
{
"topic": "movies",
"key": null,
"value": {
"id": 128,
"title": "The Big Lebowski",
"release_year": 1998
},
"partition": 0,
"offset": 3
},
{
"topic": "movies",
"key": null,
"value": {
"id": 780,
"title": "Super Mario Bros.",
"release_year": 1993
},
"partition": 0,
"offset": 4
},
{
"topic": "movies",
"key": null,
"value": {
"id": 101,
"title": "Chariots of Fire",
"release_year": 1981
},
"partition": 0,
"offset": 5
}
]
Так понятнее, но всё равно много лишнего. Допустим, мы хотим видеть только названия фильмов и годы выпуска. Это легко сделать с помощью jq:
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \
http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records | jq \
| jq '.[] | {title: .value.title, year: .value.release_year}'
{
"title": "Die Hard",
"year": 1988
}
{
"title": "Tree of Life",
"year": 2011
}
{
"title": "A Walk in the Clouds",
"year": 1995
}
{
"title": "The Big Lebowski",
"year": 1998
}
{
"title": "Super Mario Bros.",
"year": 1993
}
{
"title": "Chariots of Fire",
"year": 1981
}
Давайте посмотрим, что у нас получилось (можете проделать то же самое в jqplay):
- Мы передали выходные данные из REST Proxy в jq. В одинарных кавычках выполняется программа jq с двумя шагами. jq использует вертикальную черту, чтобы передать выходные данные из одного шага как входные для другого.
- В нашем примере первый шаг — это итератор, который считывает запись каждого фильма из массива и передаёт её на следующий шаг.
- На втором шаге создаётся новый объект JSON из каждой записи. Ключи произвольные, а значения берутся из выходных данных с помощью оператора identity, '.'.
С jq можно делать много интересного. Изучите документацию.
Обработка данных JSON в jq позволяет нам сочетать разные операции для достижения желаемого результата. Это напоминает мне о Kafka Streams и нашем последнем инструменте.
Kafka Streams Topology Visualizer
Kafka Streams Topology Visualizer обрабатывает текстовое описание топологии Kafka Streams и графически изображает входные топики, обрабатывающие ноды, промежуточные топики, хранилища состояний и т. д. Это отличный способ получить общее представление о сложной топологии Kafka Streams. В руководстве по оценке фильмов топология не такая уж и сложная, но хорошо послужит для иллюстрации.
Текстовое представление топологии, полученное с помощью метода Topology::describe:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [movies])
--> KSTREAM-MAP-0000000001
Processor: KSTREAM-MAP-0000000001 (stores: [])
--> KSTREAM-SINK-0000000002
<-- KSTREAM-SOURCE-0000000000
Sink: KSTREAM-SINK-0000000002 (topic: rekeyed-movies)
<-- KSTREAM-MAP-0000000001 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000010 (topics: [KSTREAM-MAP-0000000007-repartition]) --> KSTREAM-JOIN-0000000011
Processor: KSTREAM-JOIN-0000000011 (stores: [rekeyed-movies-STATE-STORE-0000000003])
--> KSTREAM-SINK-0000000012
<-- KSTREAM-SOURCE-0000000010 Source: KSTREAM-SOURCE-0000000004 (topics: [rekeyed-movies]) --> KTABLE-SOURCE-0000000005
Sink: KSTREAM-SINK-0000000012 (topic: rated-movies)
<-- KSTREAM-JOIN-0000000011 Processor: KTABLE-SOURCE-0000000005 (stores: [rekeyed-movies-STATE-STORE-0000000003]) --> none
<-- KSTREAM-SOURCE-0000000004 Sub-topology: 2 Source: KSTREAM-SOURCE-0000000006 (topics: [ratings]) --> KSTREAM-MAP-0000000007
Processor: KSTREAM-MAP-0000000007 (stores: [])
--> KSTREAM-FILTER-0000000009
<-- KSTREAM-SOURCE-0000000006 Processor: KSTREAM-FILTER-0000000009 (stores: []) --> KSTREAM-SINK-0000000008
<-- KSTREAM-MAP-0000000007
Sink: KSTREAM-SINK-0000000008 (topic: KSTREAM-MAP-0000000007-repartition)
<-- KSTREAM-FILTER-0000000009
Даже если вам по этому описанию всё понятно, поверьте, большинству людей гораздо удобнее использовать графическую схему.
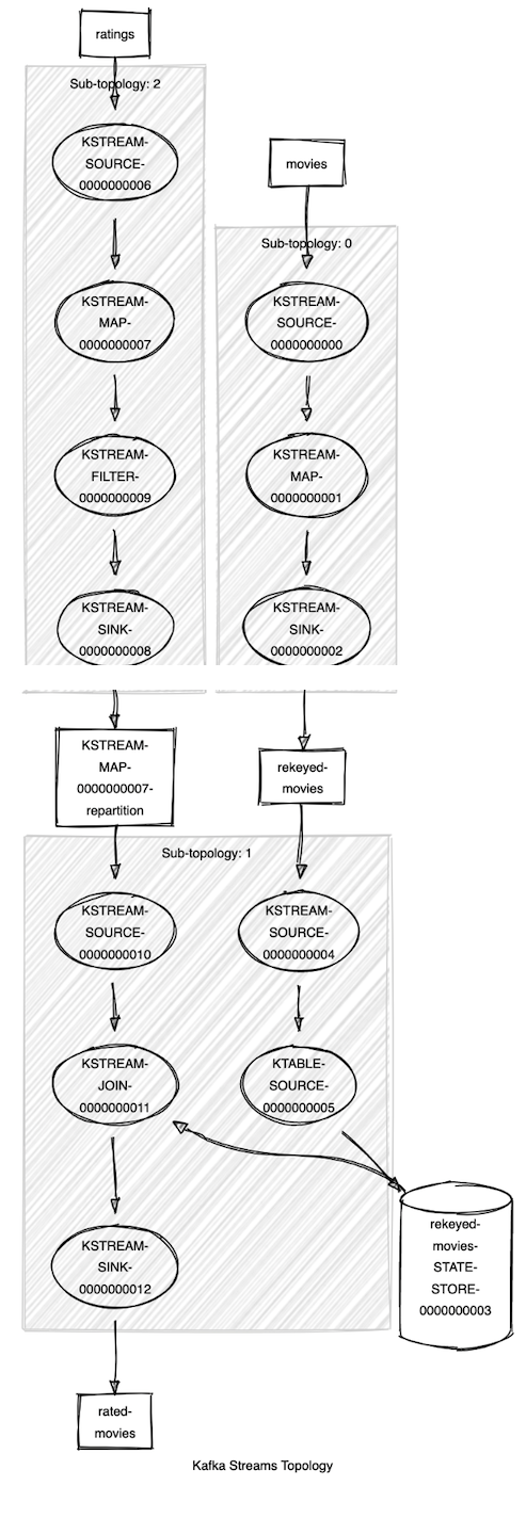
Kafka Streams Topology Visualizer — это веб-приложение, которое можно разместить в своей среде (загрузив с GitHub). Если вы используете его время от времени, достаточно будет общедоступной версии.
Сложную топологию неудобно изучать целиком, поэтому можно визуализировать ее частями, а потом объединить изображения. Это особенно удобно, когда новому разработчику нужно быстро изучить существующее приложение Kafka Streams.
Топологии ksqlDB
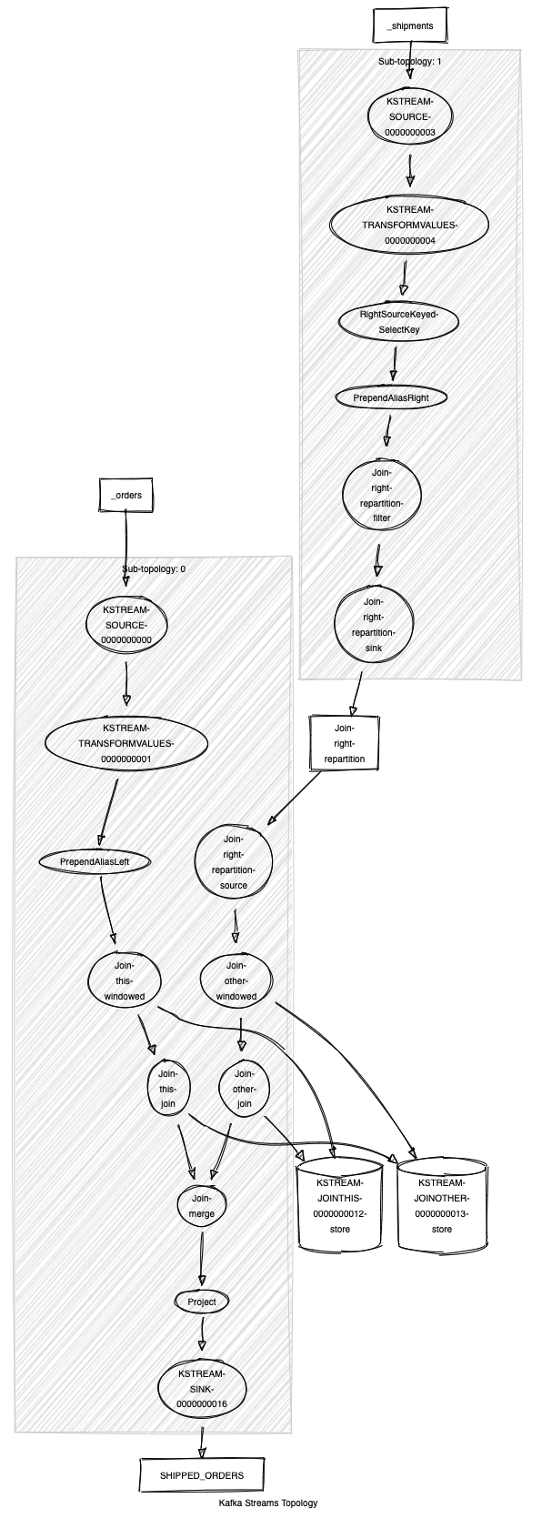
ksqlDB — это база данных потоковой передачи событий, с помощью которой можно создавать сложные топологии, используя синтаксис, знакомый каждому разработчику SQL. Поскольку ksqlDB создается поверх Kafka Streams, Kafka Streams Topology Visualizer работает и с этими типами топологий.
Получаем описание топологии из ksqlDB командой EXPLAIN. Для начала находим исполняющий запрос:
ksql> SHOW QUERIES;
Query ID | Query Type | Status | Sink Name | Sink Kafka Topic | Query String
--------------------------------------------------------------------------------------------------------------------------
CSAS_SHIPPED_ORDERS_0 | PERSISTENT | RUNNING:1 | SHIPPED_ORDERS | SHIPPED_ORDERS | CREATE STREAM SHIPPED_ORDERS WITH
...
Теперь можно использовать созданное имя запроса CSAS_SHIPPED_ORDERS_0 для получения топологии:
ksql> EXPLAIN CSAS_SHIPPED_ORDERS_0;
Выходные данные будут объемными, так что здесь мы их приводить не будем. Копируем и вставляем описание топологии в визуализатор и получаем такую схему:
Верхушка айсберга
Мы рассмотрели четыре полезных инструмента для разработчиков Apache Kafka, но их гораздо больше, и это одно из преимуществ работы с таким активным сообществом. Если вы знаете полезный инструмент командной строки или графическое приложение для Kafka, расскажите об этом на форуме Confluent Community Forum.
→ Курс «Apache Kafka База»



