
Мы рассмотрим распространённые ситуации, в которых события нужно отправлять повторно в исходном порядке. Для примера возьмём приложение, которое потребляет события из одного топика, преобразует их и создает выходные данные в целевом топике.
Материал подготовлен на основе перевода оригинальной статьи в блоге Confluent, автор – Gerardo Villeda.
Паттерн 1: остановка на ошибке
Это сценарии, в которых все входные события должны обрабатываться по порядку, без исключений. Например, поток отслеживания изменённых данных из базы данных.
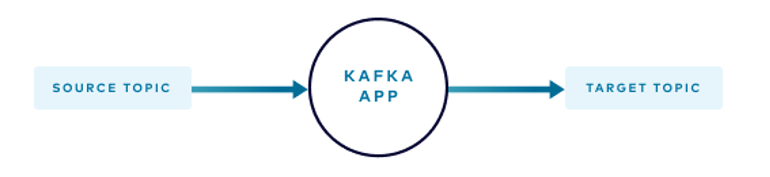
На схеме ниже показано, как события из исходного топика обрабатываются или преобразуются и публикуются в целевом топике. Ошибка в процессе заставляет приложение остановиться и ждать вмешательства человека. События из исходного топика не могут пойти по другому пути.
Паттерн 2: очередь недоставленных сообщений (Dead Letter Queue)
Если приложение не может обработать события, они перенаправляются в топик ошибок, а основной поток продолжается. При таком подходе у нас нет повторных попыток — событие или обрабатывается, или отправляется в топик ошибок.
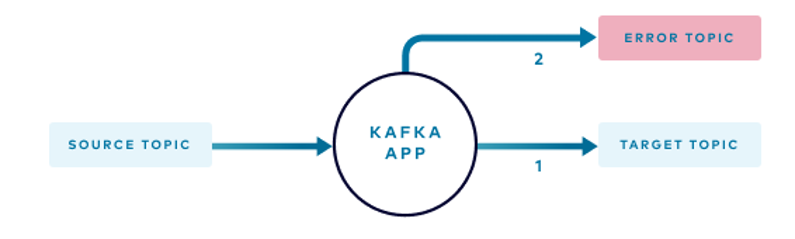
На схеме показано, что у событий из исходного топика есть два пути:
- В обычных обстоятельствах приложение обрабатывает каждое событие из исходного топика и публикует результат в целевом топике.
- Если событие невозможно обработать, например, у него неправильный формат или нет обязательных атрибутов, оно отправляется в топик ошибок.
Паттерн 3: добавление приложения и топика повторных попыток
Что будет, если приложение пытается обработать событие, но условия обработки не соблюдаются? Представьте приложение, которое обрабатывает запросы на закупку товаров. Цена товара поступает из другого приложения и может отсутствовать в момент получения запроса.
Если добавить топик повтора (retry topic), можно будет обработать большинство событий сразу, а остальные — как только условия будут соблюдены. В этом примере мы отправляем события в топик повтора, если при попытке обработки была недоступна цена товара. Это не должно считаться ошибкой, и периодически нужно пытаться обработать событие.
В контейнеризированной среде для повторных попыток можно выделить один или два инстанса, потому что по этому пути будет отправляться мало событий.
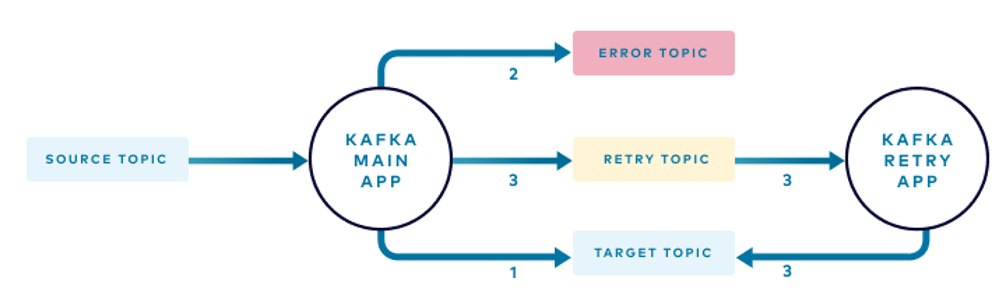
На схеме показано, что у события из исходного топика есть три пути:
- В обычных обстоятельствах приложение обрабатывает каждое событие из исходного топика и публикует результат в целевом топике.
- Если событие невозможно обработать, например, у него неправильный формат или нет обязательных атрибутов, оно отправляется в топик ошибок.
- События, для которых отсутствуют необходимые данные, отправляются в топик повтора, где инстанс повторных попыток вашего приложения периодически пытается их обработать.
Связанные события могут обрабатываться не по порядку
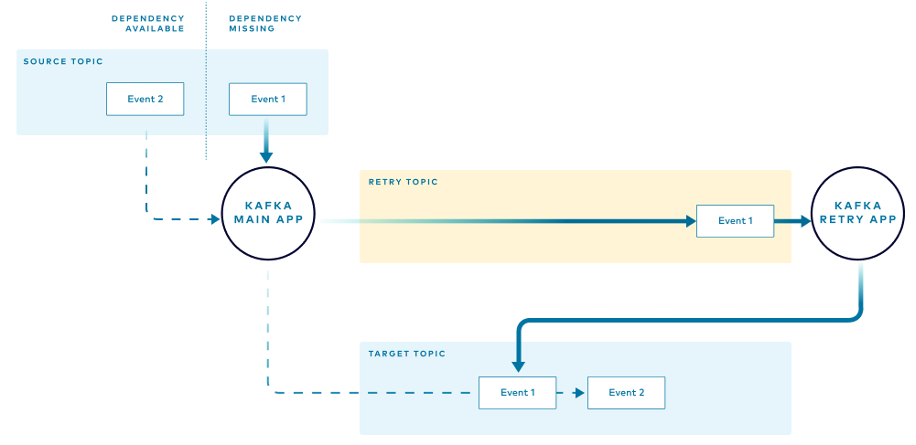
Важное примечание для этого паттерна: нельзя гарантировать, что события будут обрабатываться в том же порядке, в котором поступили из исходного топика, ведь путь повторных попыток дольше и обычно медленнее, потому что инстансов повторных попыток меньше.
На схеме показано, что первое полученное событие (Event 1) достигает целевого топика после события, которое было получено позже (Event 2). Используйте этот паттерн, только если согласны на такое поведение.
Паттерн 4: сохранение порядка перенаправленных событий
Предыдущий паттерн подразумевал отправку событий в топик повтора до соблюдения определённых условий, но порядок сообщений при этом мог нарушаться.
В некоторых сценариях мы должны сохранять порядок. Например, приложение меняет количество товара в наличии, и если количество опускается ниже 10, создаётся запрос на закупку. Сейчас у вас 10 единиц товара, и если сначала произошло событие увеличения, а затем событие уменьшения, но мы обработаем их в обратном порядке, можно случайно создать запрос на закупку. Если количество будет ниже 0, возникнет ошибка.
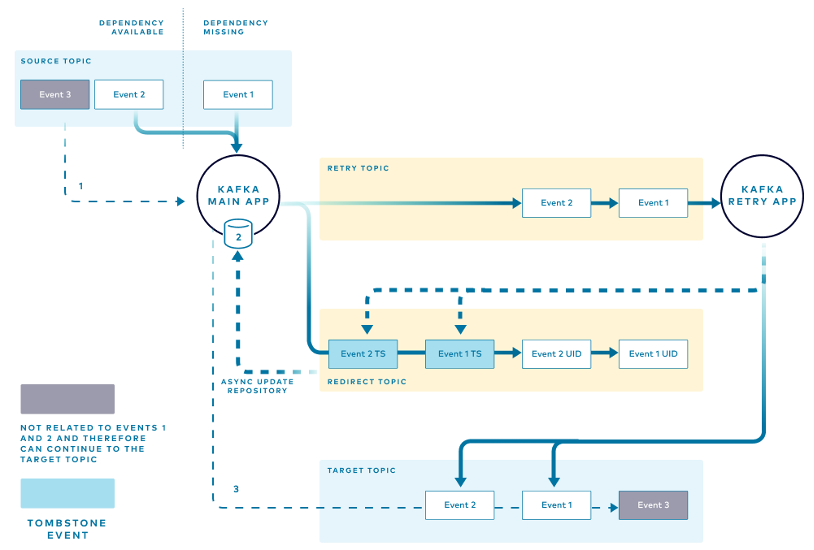
Этот паттерн помогает решить проблему: главное приложение должно отслеживать каждое событие, отправляемое в топик повтора. Когда условие не соблюдается (например, отсутствует цена), главное приложение сохраняет уникальный идентификатор события в локальной структуре in-memory. Уникальные идентификаторы группируются по товару, которому принадлежат. Приложение знает, что для событий, связанных с определённым товаром, выполняются повторные попытки, поэтому последующие события для этого товара нужно отправлять по пути повторных попыток, чтобы сохранить порядок.
Когда поступает первое событие с отсутствующими зависимостями, главное приложение:
- Записывает уникальный ID сообщения (с группировкой по товару) в локальное хранилище in-memory.
- Отправляет событие в топик повтора, добавляя заголовок с уникальным ID сообщения. Когда ID сообщения добавляется как заголовок, исходное сообщение защищено от изменений, и, как объясняется ниже, приложение для повторных попыток сможет опубликовать нужное событие tombstone после завершения ретрая.
- Публикует уникальный ID полученного сообщения в топик перенаправления.
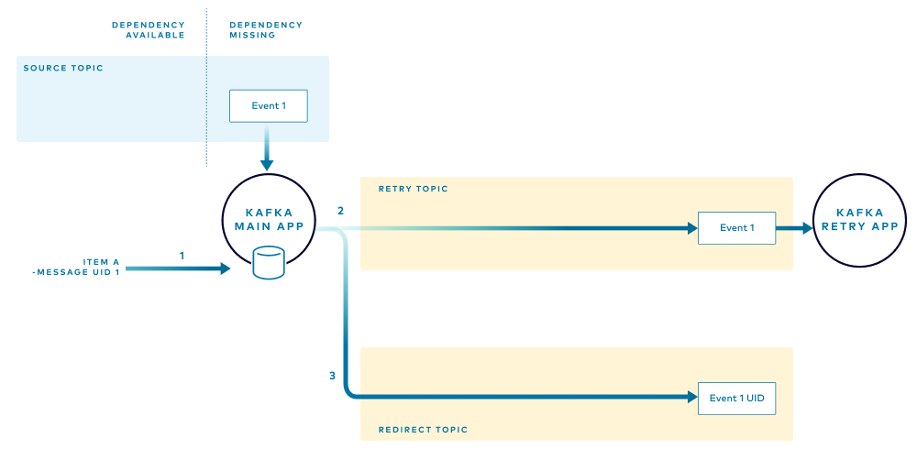
Когда поступает следующее событие, приложение проверяет локальное хранилище на наличие событий для этого товара. Если они найдены, приложение понимает, что какие-то события ждут повторной попытки, и направляет новое событие в поток повтора.
Например, приложение получает события для товара А, для которого уже есть события, нуждающиеся в повторных попытках. Приложение не пытается обработать событие, а перенаправляет его в поток повторных попыток. Таким образом все события для товара А обрабатываются в порядке получения. Приложение добавляет уникальный идентификатор для нового события в локальное хранилище и перенаправляет событие в топики повтора и перенаправления, как раньше.
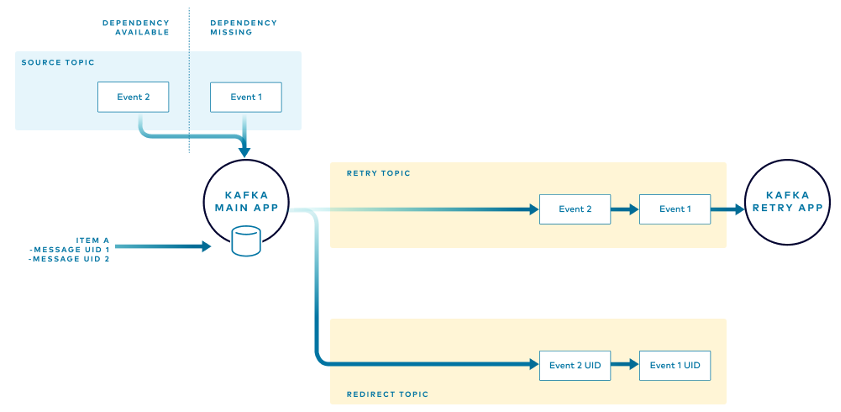
Приложение для повторных попыток обрабатывает события в топике повторных попыток в порядке получения. Когда повторная попытка завершается успехом и событие публикуется в целевом топике, инстанс приложения повторных попыток отправляет подтверждение в форме события tombstone в топик перенаправления. Для каждого события с успешной повторной попыткой публикуется одно событие tombstone.
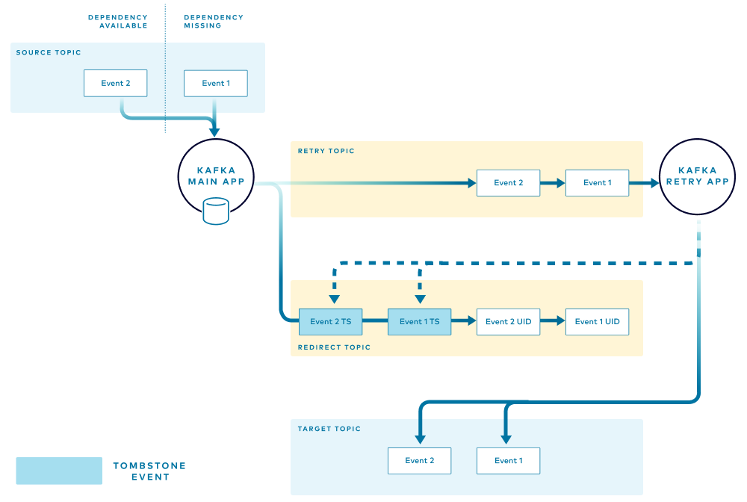
Главное приложение проверяет топик перенаправления на предмет событий tombstone, которые сигнализируют об успешных ретраях. Приложение удаляет сообщения из хранилища в памяти. Это позволяет обрабатывать последующие события для того же товара через основной поток.
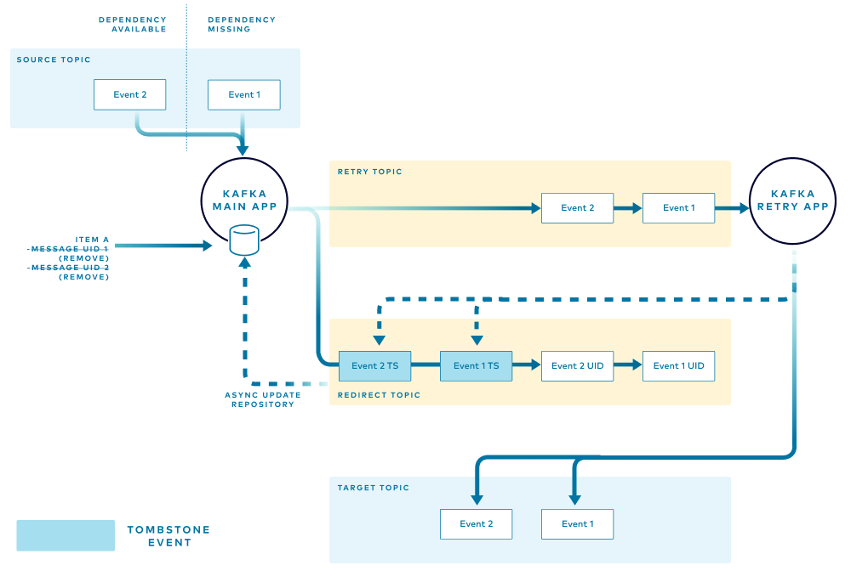
На этой схеме изображён путь, который проходит событие для товара, если у него есть все обязательные зависимости и оно может следовать обычному процессу. Главное приложение:
- Считывает событие из исходного топика.
- Ищет в локальном хранилище записи о пути повторных попыток.
- Обрабатывает событие и публикует его в целевом топике.
Восстановление
В случае сбоя хранилище in-memory, которым управляло главное приложение, пропадёт. Но его можно легко восстановить, считав события из топика перенаправления и инициализировав хранилище in-memory.
Заключение
Любые приложения должны уметь обрабатывать ошибки и повторные попытки, и приложения Kafka не исключение. Описанные подходы охватывают не все аспекты. Это просто общие рекомендации, которые можно адаптировать к своим потребностям.
→ Курс «Apache Kafka База»



