
Оригинал: Microservices Apache Kafka Domain Driven Design
Микросервисы тесно связаны с предметно-ориентированным проектированием (Domain-Driven Design, DDD). Это такой подход к проектированию, при котором для программного обеспечения продумывается и постоянно развивается бизнес-модель — независимо от физической инфраструктуры, на которой все это работает. Всё чаще этот подход упоминается в связи с Apache Kafka.
В таких проектах архитектура микросервисов использует Kafka для стриминга событий. При предметно-ориентированном проектировании мы определяем ограниченные контексты (bounded contexts) для бизнес-процессов, которые нужно реализовывать приложению. Вместе с событиями эти контексты создают однонаправленную схему зависимостей, где каждый ограниченный контекст отделен от нижестоящих. В итоге мы получаем бизнес-приложения с развитым стримингом событий.
В этой статье мы поговорим о том, почему Apache Kafka де-факто стала стандартом и основой архитектуры микросервисов. Kafka не только заменяет другое промежуточное ПО, но и позволяет создавать сами микросервисы с помощью DDD и нативных API Kafka, таких как Kafka Streams, ksqlDB и Kafka Connect.
Микросервисы
Сейчас все говорят о создании гибкой архитектуры с помощью микросервисов, причем этот термин используется в самых разных контекстах.
Хотя с микросервисами все не так просто, у них много преимуществ, включая разделение на компоненты, при котором мы создаем децентрализованную архитектуру на основе бизнес-процессов. Умные эндпоинты и глупые каналы обеспечивают нам вот что:
Приложения на микросервисах максимально независимы и сфокусированы на одной задаче — у них своя логика предметной области [которая применяется к отдельной части бизнес-задачи], и в этом смысле они похожи скорее на фильтры в классическом Unix-овом понимании: они получают запрос, применяют нужную логику и выдают ответ.
Мартин Фаулер (Martin Fowler)
Apache Kafka — платформа потоковой обработки событий для микросервисов
Какая технология нужна для создания архитектуры микросервисов? Ответ состоит из двух частей:
1. Как микросервисы будут общаться друг с другом?
Если речь о взаимодействии микросервисов, в первую очередь, в голову приходит REST, то есть обмен данными с помощью синхронных вызовов HTTP(S). Этот вариант подходит для большинства сценариев. Но модель «запрос-ответ» подразумевает соединение между точками, то есть отправитель привязан к получателю и наоборот, так что сложно изменить один компонент, не затронув другой.
Поэтому многие архитекторы используют промежуточное ПО как основу для взаимодействия микросервисов, чтобы создавать независимые, масштабируемые и высокодоступные системы. Для этой прослойки можно использовать что угодно — связующий код или фреймворк, брокер сообщений, вроде RabbitMQ, инструмент ETL (Talend), ESB (WSO2) или платформу потоковой обработки событий, например, Apache Kafka.
2. Какое промежуточное ПО мы используем (если используем)?
Популярность Apache Kafka для микросервисов можно объяснить тремя преимуществами платформы:
- Публикация и подписка на потоки событий, как в очереди сообщений или корпоративной системе обмена сообщениями.
- Отказоустойчивое хранение потоков событий.
- Обработка потоков событий в реальном времени, по мере поступления.
Благодаря этим трём преимуществам в одной распределённой платформе потоковой обработки событий можно разделять микросервисы (продюсеры и консьюмеры), при этом обеспечивая надежность, масштабируемость и отказоустойчивость.

Чтобы лучше понять, чем Apache Kafka лучше традиционных инструментов, вроде MQ, ETL или ESB, прочитайте Apache Kafka vs. Enterprise Service Bus – Friends, Enemies or Frenemies?
Но где связь между Apache Kafka и предметно-ориентированным проектированием?
DDD для создания и разделения микросервисов
Подход DDD впервые был описан в книге Эрика Эванса (Eric Evans). Он используется для создания систем со сложной предметной областью бизнеса. DDD ориентировано не на инфраструктуру, роутеры, прокси и кэширование, а на бизнес-логику для решения реальных бизнес-задач. Это отличный способ отделить создание бизнес-моделей от кода, который соединяет все вместе. Когда бизнес-логика существует отдельно от соединительного (plumbing) кода, программное обеспечение проще проектировать, моделировать, собирать и развивать.
Принципы DDD:
- Описываем модель предметной области в бизнес-терминах, в сотрудничестве со специалистами в этой области.
- Используем термины предметной области в коде.
- Защищаем независимость предметной области от других предметных областей, технических сфер и т. д.
Главная концепция DDD в этом смысле — ограниченный контекст (bounded context). В крупных проектах обычно много разных предметных моделей и ограниченных контекстов. Если мы объединим код из разных ограниченных контекстов, получим ненадежный и сложный для понимания продукт с кучей ошибок. Члены команды перестанут понимать друг друга и не будут знать, в каком контексте не следует применять ту или иную модель.
DDD требует явно определять контекст для применения модели. Мы должны установить границы и обозначить, какая команда отвечает за эту модель, как она будет использоваться в конкретных частях приложения, как она будет воплощаться физически, в кодовых базах и схемах баз данных. Когда мы помещаем модель в строго определённые границы, нам проще понять и реализовать каждый компонент, потому что мы работаем с одним ограниченным контекстом. Мы не отвлекаемся на код, который мог просочиться к нам извне. Как удачно сформулировал Дэн Норт (Dan North): Создавайте код, который помещается у вас в голове.
Применительно к платформе потоковой обработки событий эти принципы можно выразить примерно так:
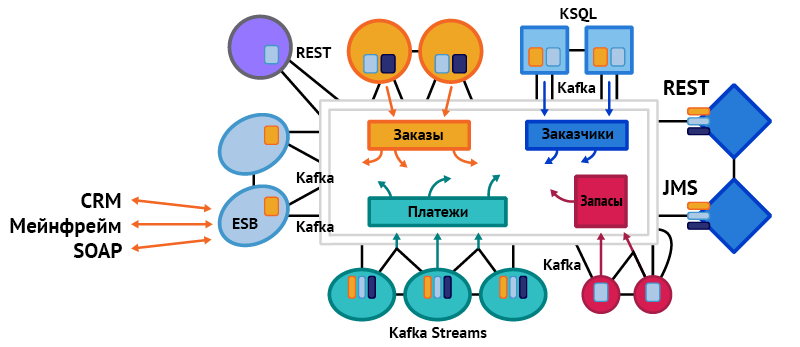
Здесь у каждого микросервиса свой ограниченный контекст. С технической точки зрения, сюда могут входить разные API, фреймворки, протоколы передачи данных и хранилища данных. Тут можно использовать подход «запрос-ответ» или события — в зависимости от задачи, которую мы решаем. В любом случае у нас будет отдельный ограниченный контекст и отдельная предметная модель, а также связи между этой моделью, бизнес-процессами и данными, которые она делит с другими моделями.
Почему сюда так хорошо вписывается Kafka?
Apache Kafka и микросервисы на основе предметных областей
Apache Kafka хранит полученные сообщения, так что продюсеры и консьюмеры существуют совершенно независимо друг от друга:
- Компоненты на стороне сервера (брокер Kafka, ZooKeeper и Confluent Schema Registry) можно отделить от бизнес-приложений.
- Продюсерам не важно, кто потребляет сообщения. Все вопросы с backpressure, масштабированием и высокой доступностью Kafka решает за них.
- Продюсеры могут создавать события, даже когда консьюмеры не работают.
- Новые консьюмеры можно создавать в любое время, причем они могут извлекать события, начиная с таймстампа из прошлого.
- Консьюмеры обрабатывают данные в своем темпе (пакетами или в реальном времени).
- Консьюмеры могут обрабатывать данные снова и снова (например, для обучения аналитических моделей или восстановления после ошибок или повреждения данных).
При таком подходе каждая команда проекта будет работать со своей предметной областью и отвечать за её SLA, управление версиями и выбор технологий.
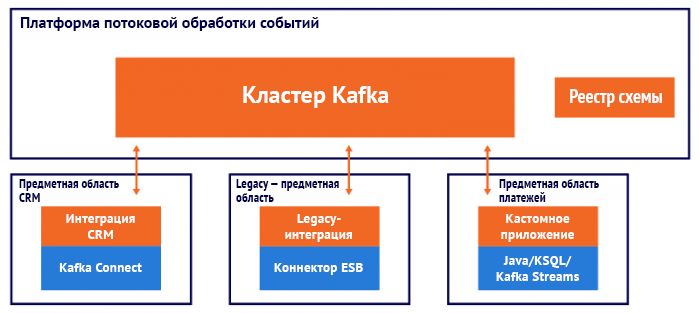
Эта схема может относиться не только к бизнес-приложениям, но и к операциям в IT-отделе компании, отвечающем за кластер Kafka, где размещаются решения для использования внутри компании. Кластер Kafka часто развёртывается в инфраструктуре PaaS, например, Kubernetes и Confluent Operator. В облачных развёртываниях, где используются управляемые сервисы, вроде Confluent Cloud, обычно не нужны команды инфраструктуры.
Предметные модели, ограниченные контексты и единый язык
Мы уже сказали, что основной принцип DDD — выражение бизнес-задачи в виде коллекции независимых ограниченных контекстов. У каждого контекста есть предметная модель, которая в ПО включает все необходимые данные, бизнес-операции и терминологию для их описания. Как предметные модели в разных ограниченных контекстах связаны друг с другом? Как гарантировать, что изменения в одной модели не помешают другим моделям?
Для этого мы используем так называемый антикоррупционный слой (anti-corruption layer), который сопоставляет данные, используемые в одной предметной модели, с данными, передаваемыми между разными микросервисами или ограниченными контекстами. Этот паттерн не зависит от реализации, то есть его можно использовать и с событиями, и с подходом «запрос-ответ». В обоих случаях обычно используется протокол передачи данных (будь то схема для возврата данных из эндпоинта REST или схема, которая описывает событие, например, сообщение Avro в Schema Registry).
Антикоррупционный слой выполняет две задачи:
- Защищает предметную модель от изменений.
- Представляет границу между контекстами и описывает их связь в техническом смысле (поле A в сообщении связано с полем B в модели) и в терминах единого языка DDD — контрагент в схеме событий сопоставляется с заказчиком в предметной модели.
Чтобы модель в каждом ограниченном контексте можно было развивать, нужно тщательно продумать интерфейсы, которые связывают их друг с другом. Для этого нужно, в первую очередь, договариваться о едином языке, который создаётся не только разработчиками, но и представителями бизнеса.
Соединение предметных областей с помощью Apache Kafka, Kafka Streams, ksqlDB и Kafka Connect
Стоит отметить, что Apache Kafka — это не просто система обмена сообщениями или слой интеграции. Это платформа потоковой обработки событий. Это значит, что она не только предоставляет прослойку для разделения микросервисов, но и позволяет выполнять сложные операции с данными, например, разделение, соединение, фильтрацию и обобщение в клиентском коде. Вот еще одно отличие Apache Kafka от традиционного промежуточного ПО с точки зрения ThoughtWorks:
…мы наблюдаем, как некоторые организации воссоздают антипаттерны ESB с Kafka — централизуют компоненты экосистемы Kafka, например, коннекторы и обработчики потоков вместо того, чтобы оставить их в ведении команд по продукту или сервису. Это похоже на очень нехорошие антипаттерны с ESB, когда всё больше логики, оркестрации и трансформации передаётся в централизованно управляемую ESB, так что возникает сильная зависимость от центральной команды. Пожалуйста, не совершайте таких ошибок.
Recreating ESB Antipatterns with Kafka
Это важное замечание. ESB включали логику, оркестрацию и трансформацию не просто так, а потому что так нужно было бизнес-процессам. Проблема, на которую указывают ThoughtWorks, не в том, что это были какие-то особо сложные или ненужные процессы. Просто они почему-то внедрялись в централизованную инфраструктуру, за пределами приложений, где им самое место. Такая централизация инфраструктуры и бизнес-логики приводила к хрупкому ПО, которое сложно было развивать. Это как раз то, чего следует избегать в современном agile-проекте, включающем разработку.
Системы потоковой обработки событий используют другой подход. У них глупые (но хорошо масштабируемые) каналы и умные фильтры, но главное — эти фильтры гораздо более эффективные и функциональные, чем любые инструменты до них. Фильтр, встроенный в микросервис, оснащён всеми возможностями современного движка потоковой обработки. Никакой централизованной логики нет. Все полностью децентрализованно, то есть у каждого ограниченного контекста своя бизнес-логика, оркестрация, трансформация и т. д.
Используя Kafka в качестве «центральной нервной системы», можно ещё больше абстрагировать сопоставление моделей в разных ограниченных контекстах.
Так мы сможем использовать все плюсы DDD без проблем, присущих ESB, — тесно связанного и централизованного управления общим бизнес-процессом.
Способ реализации каждого микросервиса зависит только от команды, которая им занимается. Микросервис может использовать простой технический интерфейс, вроде REST или JMS, который будет только служить посредником в коммуникации. В качестве альтернативы можно создать микросервисы с полноценным стримингом событий, которые будут внутренне использовать все преимущества потоковой обработки для управления потоками событий и сопоставлять их с внутренней моделью.
В примере выше показаны разные микросервисы. Одни используют REST (например, для взаимодействия между микросервисами и пользовательским интерфейсом), другие — Kafka Streams или ksqlDB для объединения событий из разных источников. Некоторые используют Kafka Connect, чтобы просто пушить события в базу данных, где они проходят дальнейшую обработку или используются напрямую с помощью паттерна генерации событий (event sourcing). Техническая реализация для каждого микросервиса не зависит от технологий, которые используются в других микросервисах.
Как создать такую систему
Как создать отдельные микросервисы со стримингом событий через REST, gRPC или другой протокол запросов и ответов — и так понятно. Создание системы на основе событий требует совсем другого подхода. События могут быть использованы для построения систем самыми разными способами. Например, их можно использовать как сообщения без подтверждения (fire-and-forget) или как инструменты для совместной работы. Бен Стопфорд (Ben Stopford) в статье Build Services on a Backbone of Events подробно объясняет эти паттерны.
Также нужно решить, как мы будем управлять состоянием. Можно делать это в базе данных с помощью Kafka Connect или управляемого сервиса с использованием Kafka Streams API. Бен Стопфорд (Ben Stopford) подробно описывает stateful стриминг событий в микросервисах в статье Building a Microservices Ecosystem with Kafka Streams and ksqlDB.
Чтобы узнать больше о том, как Connect, Kafka Streams и микросервисы работают вместе, прочите эту подробную статью от Евы Бызек (Yeva Byzek). Наконец, создание экосистемы микосервисов — это только первый шаг. После создания их нужно мониторить, контролировать и поддерживать. Узнайте, как это делать.
Confluent предлагает функции RBAC для контроля доступа на основе ролей на Confluent Platform. Мы можем детально настроить, какие ресурсы (топик Kafka, Schema Registry или коннектор) будут доступны команде каждой предметной области.
Просто выберите архитектуру, которая больше всего вам подходит. Например, каждым кластером Kafka Connect может управлять команда предметной области. Или Kafka Connect может быть частью кластера Kafka, а команды будут развёртывать коннекторы для него.
Надеюсь, вам помог этот обзор инструментов для создания и использования систем на основе микросервисов в рамках подхода DDD.
Apache Kafka + DDD = разделённые микросервисы с потоками событий
Создать архитектуру микросервисов можно разными способами, и предметно-ориентированное проектирование, несомненно, один из лучших подходов. Особенно если мы создаем системы со сложной предметной бизнес-областью (здравоохранение, финансы, страхование, ритейл).
Многие принципы проектирования DDD можно напрямую применять к системам на основе событий, в том числе не описанным в этой статье. Я обозначил самые распространённые технические трудности: как выделить приложение в ограниченный контекст, почему так важны отдельные контексты, зачем нужны предметные модели и как всё это связано с обменом сообщениями, Apache Kafka и событиями.
Учитывая широкий набор доступных инструментов, архитектура микросервисов много выигрывает при использовании платформы потоковой обработки событий для разделения микросервисов. Мы можем использовать запросы, простые системы на основе событий, целые бизнес-приложения с потоками событий или комбинацию этих методов. DDD предоставляет фундамент, чтобы управлять взаимодействием между всеми компонентами, включая единый язык, ограниченные контексты, схемы и антикоррупционные слои. Как мы видели, события и сообщения помогают этим системам функционировать на практике.
Минутка рекламы

Можно долго читать книги или статьи по Kafka, смотреть обучающие видео или изучать документацию. Потратить на это много времени и все равно не найти всей информации, чтобы стать мастером.
А мы подготовили курс Apache Kafka База, где ты за 6 недель начнешь разбираться в Kafka, как будто создал её сам.

