
В Apache Cassandra можно настроить очень много параметров. Один из них — num_tokens. Он находится в файле cassandra.yaml вместе с другими параметрами, но, в отличие от многих из них, у него есть дефолтное значение. Суть в том, что большинство параметров Cassandra влияют на кластер только в одном аспекте, а если изменить значение num_tokens, вместе с ним поменяется многое. Команда Apache Cassandra представила изменение CASSANDRA-13701, чтобы уменьшить дефолтное значение num_tokens с 256 до 16. Это важно. Чтобы понять последствия изменения, давайте разберемся, какую роль играет num_tokens в кластере.
Не пытайтесь повторить это в продакшене
Осторожно: никогда-никогда не меняйте параметр num_tokens на ноде после присоединения к кластеру. Как минимум, нода упадет при рестарте. У всех нод в датацентре должно быть одинаковое значение для этого параметра. Исторически так сложилось, что для гетерогенных кластеров ожидались разные значения. Случай редкий, и мы такое не советуем, но в теории можно удвоить значение num_tokens на нодах, которые аппаратно в два раза больше других. У нод в разных датацентрах обычно разные значения num_tokens. Отчасти потому, что изменить это значение в активном кластере можно с нулевым простоем. Мы не будем на этом останавливаться. Если хотите, почитайте про миграцию в новый датацентр.Основы
Параметр num_tokens влияет на то, как Cassandra распределяет данные по нодам, как данные извлекаются и перемещаются между нодами.Cassandra использует разметчик, чтобы решить, где в кластере будут храниться данные. Разметчик состоит из алгоритма хеширования, который сопоставляет ключ партиции (первую часть основного ключа) с токеном. Токен определяет, какие ноды будут содержать данные, связанные с этим ключом партиции. Каждой ноде в кластере назначается один или несколько уникальных токенов из кольца токенов (token ring). Говоря простым языком, каждой ноде назначается номер из кругового диапазона номеров, где номер — это хэш токена, а круговой диапазон номеров — кольцо токенов. Кольцо круглое, потому что за максимальным значением идет минимальное.
Назначенный токен определяет диапазон токенов в кольце, приписанный ноде. Диапазон токенов, за который отвечает нода, начинается с назначенного токена, который входит в диапазон. Минимальное значение, ближе всего расположенное к нему против часовой стрелки, в диапазон не входит и обычно принадлежит соседней ноде. Из-за кругового расположения в ноду могут входить одновременно минимальные и максимальные значения токенов в кольце. По крайней мере в одном случае минимальное значение токена против часовой стрелки будет располагаться за максимальным значением.
Например, на следующей схеме назначения токенов кольцо включает хэши от 0 до 99. Токен 10 принадлежит ноде 1. До ноды 1 в кластере располагается нода 5. Ноде 5 принадлежит токен 90. То есть ноде 1 приписаны токены с 91 по 10. В этом случае диапазон включает максимальное значение в кольце.
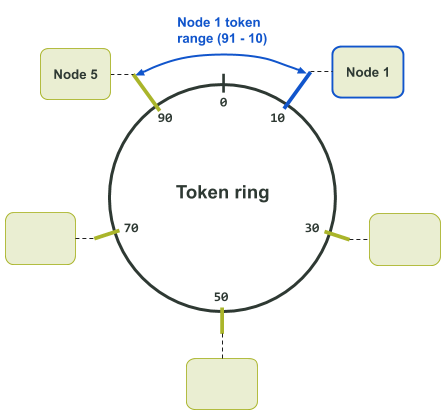
Схема выше предназначена для одной реплики данных. Дело в том, что каждому токену в кольце назначена только одна нода. Если есть несколько реплик данных, соседние ноды становятся репликами для этого токена, как показано на схеме ниже.
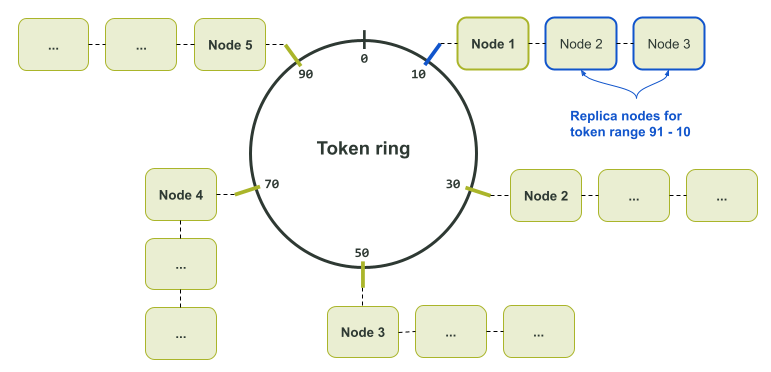
Разметчик определен как согласованный алгоритм хэширования, чтобы вы могли сколько угодно раз отправлять определенные входные данные и всегда получать одно и то же выходное значение. При таком подходе каждая нода (нода-координатор и остальные) всегда вычисляет одинаковый токен для данного ключа партиции. Вычисленный токен можно использовать, чтобы точно указать на ноду с нужными данными.
Следовательно, минимальное и максимальное значения для кольца токенов определяется разметчиком. Например, у дефолтного
Murmur3Partitioner на основе Murmur hash минимальное и максимальное значение составляют -2^63 и +2^63 - 1 соответственно. А у прежнего RandomPartitioner (на основе хэша MD5) — от 0 до 2^127 — 1. Главный минус в том, что выбрать разметчик для кластера можно только один раз. Чтобы изменить разметчик, нужно создать новый кластер и перетащить в него данные со старого.
Подробнее о хэшировании см. в документации по Apache Cassandra.
В прежние времена…
До версии 1.2 ноде можно было вручную назначить один токен с помощью параметра initial_token в файле cassandra.yaml. Тогда дефолтным разметчиком был RandomPartitioner. Хотя токены назначались вручную, разметчик незамысловато вычислял назначенные токены при настройке кластера с нуля. Например, если у вас было три кластера, нужно было разделить 2^127 - 1 на 3, чтобы получить значение начального токена. У первой ноды initial_token был бы 0, у второй — (2^127 - 1) / 3, у третьей — (2^127 - 1) / 3 * 2. В итоге у каждой ноды были диапазоны токенов одного размера.Благодаря равномерному распределению было меньше рисков перегрузки отдельных нод (если ноды на одинаковом железе, а данные так же равномерно распределены по кластеру). Неравномерное распределение токенов может приводить к появлению «горячих точек», в которых нода перегружена, потому что обслуживает больше запросов или содержит больше данных, чем другие ноды.
Хотя кластеры с назначением одного токена настраиваются вручную, деплоймент происходит в обычном режиме. Это особенно важно для очень больших кластеров Cassandra, где нод бывает больше тысячи. Одно из преимуществ такого подхода — равномерное распределение токенов.
С другой стороны, кластер с назначением одного токена гораздо сложнее расширять. Если добавить одну ноду в наш кластер из трех нод, у двух из четырех нод диапазон токенов будет меньше. Чтобы исправить эту проблему и восстановить равновесие, нужно запустить nodetool move и перераспределить токены по всем узлам. Это очень затратная операция, требующая масштабной передачи данных по всему кластеру. Альтернатива — удваивать размер кластера при каждом расширении. Правда, при этом придется задействовать больше оборудования, чем нужно. Чтобы поддерживать равномерное распределение диапазонов по нодам в таком кластере, требуется время и усилия. Или продуманная автоматизация.
Масштабирование — это только половина проблемы. Иногда это сказывается на восстановлении. Допустим, у вас есть кластер из шести нод с тремя репликами данных в одном датацентре (коэффициент репликации = 3). Реплики могут находиться на ноде 1 и 4, ноде 2 и 5 и, наконец, на ноде 3 и 6. В этом сценарии каждая нода ответственна за одну шестую каждой из трех реплик.
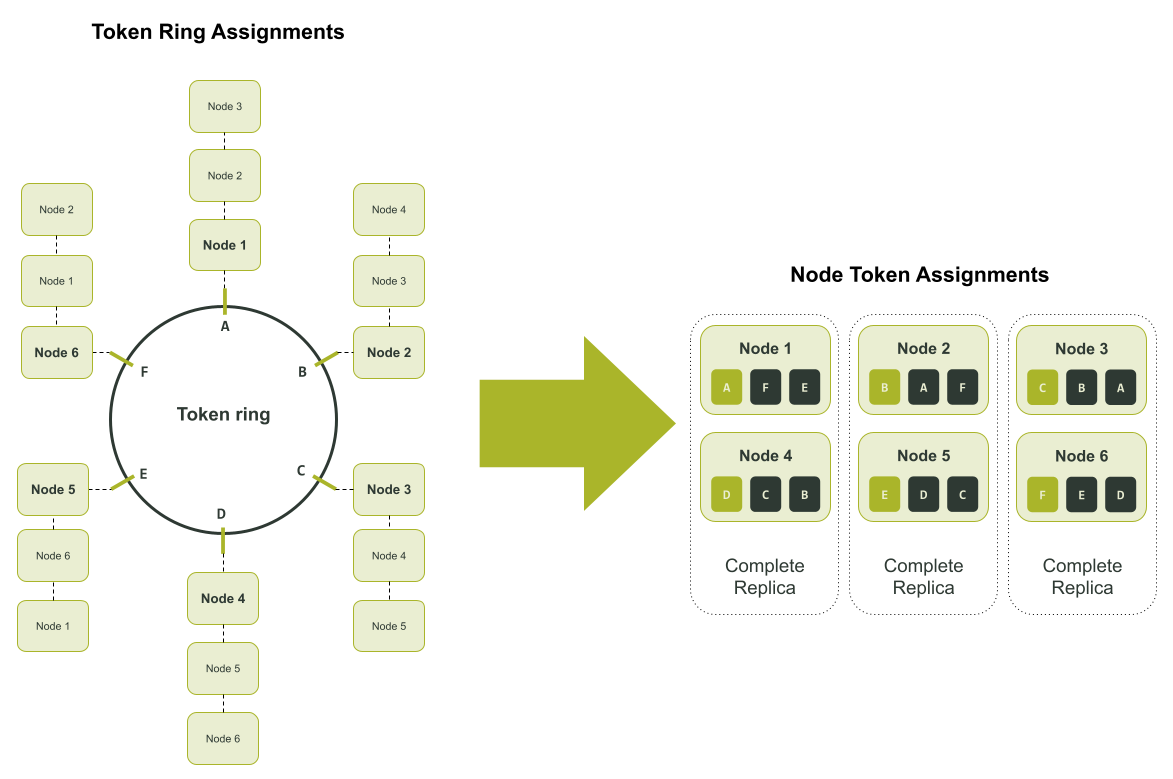
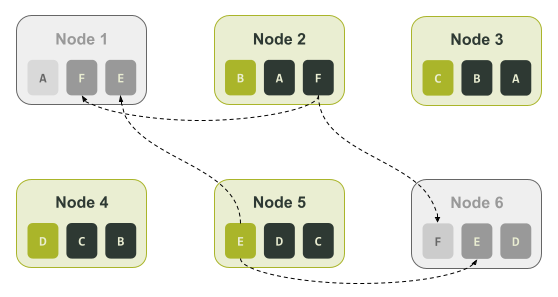
На схеме выше мы назначили токенам буквы, чтобы было проще отслеживать их назначение. Если в кластере возникает сбой и ноды 1 и 6 недоступны, для восстановления недостающих данных можно использовать только ноды 2 и 5: только на ноде 2 есть диапазон F и только на ноде 5 есть диапазон E, как показано на схеме ниже.
Виртуальные ноды спешат на помощь
Чтобы исправить недостатки единого назначения токенов, в Cassandra 1.2 добавлена возможность назначать ноде несколько диапазонов токенов. Эта функция в Cassandra называется виртуальная нода, или vnode. Виртуальные ноды представлены через CASSANDRA-4119. Исходя из описания тикета, виртуальные ноды:- Упрощают масштабирование.
- Ускоряют восстановление при сбое.
- Равномерно распределяют влияние нагрузки в случае сбоя.
- Равномерно распределяют влияние стриминговых операций.
- Лучше поддерживают однородность оборудования.
С этой функцией в файле cassandra.yaml появился параметр num_tokens. Он определяет число виртуальных нод (диапазон токенов), назначенных ноде. Чем больше это число, тем меньше диапазон. Это связано с тем, что кольцо содержит ограниченное количество токенов. Чем больше диапазонов, тем короче каждый из них.
Чтобы сохранить обратную совместимость с кластерами в версиях до 1.x, num_tokens по умолчанию имеет значение 1. Более того, параметр отключен в ванильной установке, это значение в cassandra.yaml закомментировано. Закомментированная строка и предыдущие коммиты позволяют получить представление о том, как все должно было быть.
Как уже было описано в файле cassandra.yaml и истории коммитов в git, в версии Cassandra 2.0 виртуальные узлы были включены по умолчанию. Строка num_tokens уже не была закомментирована, а дефолтное значение в ванильной установке составляло 256. Таким образом мы вошли в новую эру кластеров с относительно равномерным распределением токенов, которые легко расширять.
Благодаря дополнительным функциям и наличию 256 виртуальных нод на каждой ноде, расширять кластеры стало сплошным удовольствием. Можно было просто вставить новую ноду в кластер, и Cassandra рассчитывала и назначала токены автоматически. Значения токенов вычислялись случайным образом, поэтому по мере добавления новых нод кластер приходил в сбалансированное состояние. Благодаря этим механизмам больше не нужно было тратить часы на вычисления и операции nodetool move, чтобы расширить кластер. Тем не менее, и этот вариант по-прежнему был доступен. Если у вас был очень большой кластер или особые требования, можно было использовать параметр initial_token, закомментированный в Cassandra 2.0. В этом случае все равно надо было задавать для num_tokens число токенов, вручную определенное в параметре initial_token.
Читаем мелкий шрифт
В итоге у нас было что-то вроде персонального devops-ассистента. Мы давали ему ноду и просили добавить ее в кластер, а некоторое время спустя ей назначались токены. Но за дополнительные удобства приходится платить…Мы получаем более равномерное распределение токенов благодаря 256 узлам, но доступность начинает снижаться раньше. По иронии судьбы, чем короче диапазон токенов, тем быстрее возникает проблема недоступности данных. Если виртуальных нод мало, то есть меньше 32, возникает проблема неравномерного распределения. Cassandra распределяет токены рандомно, но эта стратегия плохо работает с маленьким числом виртуальных нод. Дело в том, что токенов слишком мало, чтобы уравновесить большую разницу в диапазонах.
Пруф или не было
Продемонстрировать проблемы с доступностью и дисбалансом диапазонов токенов можно на тестовом кластере. Настроим кластер с шестью нодами и назначением одного диапазона с помощью ccm. После вычисления токенов, настройки и запуска тестового кластера получаем следующую картину: https://xpaste.pro/p/v6PTZScUСоздаем тестовое пространство ключей (keyspace) и заполняем его с помощью cqlsh: https://xpaste.pro/p/FfwJgDzU
Чтобы проверить идеальную сбалансированность кластера, проверяем кольцо токенов.
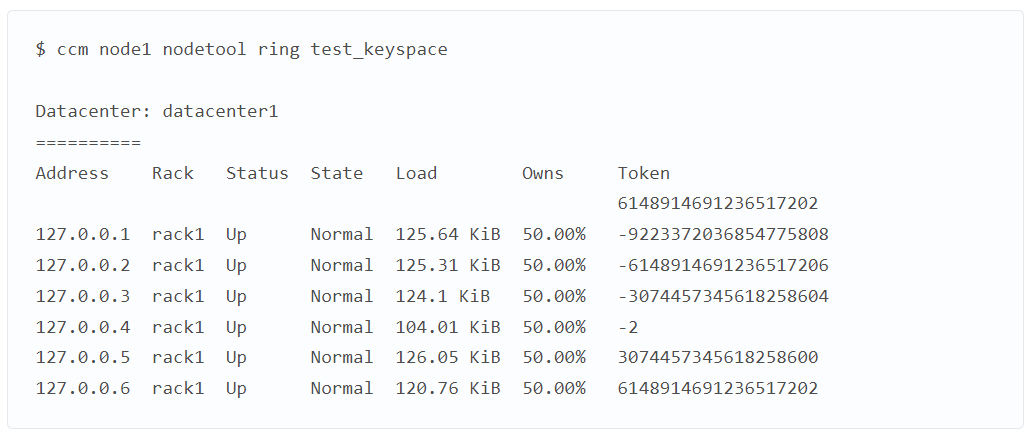
Скопировать код
В столбце Owns видно, что все ноды несут 50% ответственности за данные. Чтобы упростить пример, вручную добавим буквенное обозначение токенов. Получаем:
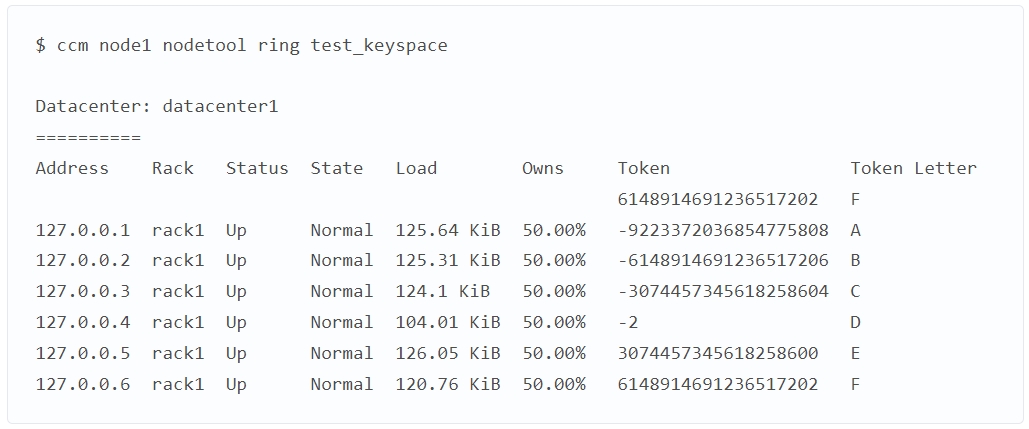
Скопировать код
Берем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы: https://xpaste.pro/p/g8odAMg8
По выходным данным, особенно по значению end_token, можно определить все диапазоны токенов, назначенные каждой ноде. Как мы уже говорили, диапазон токенов определяется значениями после предыдущего токена (start_token) вплоть до назначенного токена включительно (end_token). Нодам назначены следующие диапазоны:
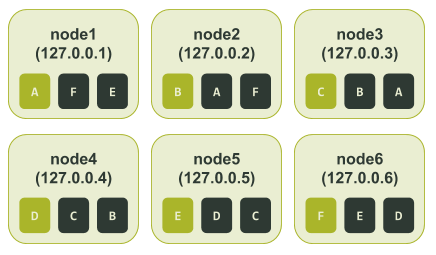
Если ноды 3 и 6 будут недоступны, мы потеряем целую реплику. Даже если в приложении настроен уровень согласованности LOCAL_QUORUM, все данные доступны. У нас остается две реплики на оставшихся четырех нодах.
Рассмотрим случай, когда кластер использует виртуальные ноды. Для примера установим число num_tokens — 3. Так будет проще понять, что происходит. Настраиваем и запускаем ноды в ccm. Тестовый кластер выглядит так.
Если в продакшене у кластера меньше 500 нод, для num_tokens лучше выбрать число побольше. См. рекомендации по продакшену для Apache Cassandra: https://xpaste.pro/p/nqLzNaXy
Мы сразу видим признаки несбалансированности в кластере. Как и в примере с назначением одного токена, здесь мы создаем тестовое keyspace и заполняем его с помощью cqlsh. Смотрим, как распределено кольцо токенов (здесь тоже добавим буквенное обозначение).
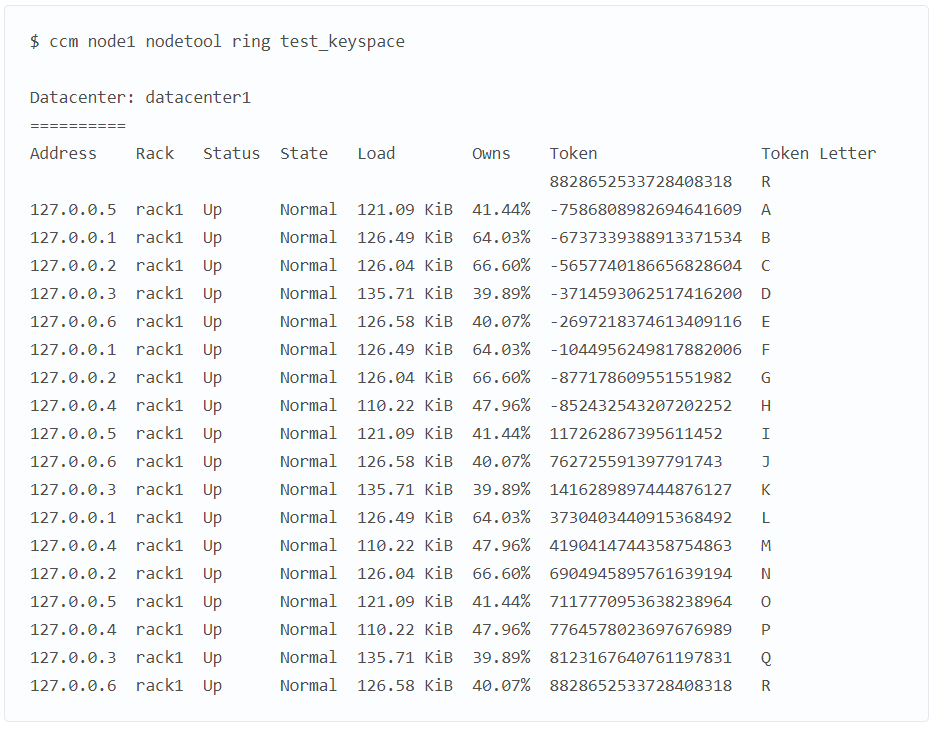
Скопировать код
В столбце Owns видим дисбаланс. У ноды 127.0.0.3 самая маленькая доля — 39.89%, а у ноды 127.0.0.2 — самая большая (66.6%). Разница в 26%!
Снова берем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы: https://xpaste.pro/p/j8BZ8W32
Наконец, смотрим, как диапазоны токенов распределены по нодам. Нодам назначены следующие диапазоны:
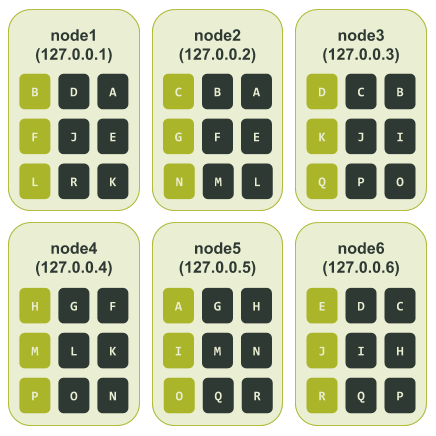
Что будет, если и здесь ноды 3 и 6 будут недоступны? Ноды 3 и 6 отвечают за токены C, D, I, J, P и Q. Выходит, что данные, связанные с этим токенами, будут недоступны, если приложение использует уровень согласованности LOCAL_QUORUM. Иными словами, в отличие от кластера с назначением одного токена, мы потеряем доступ к 33,3% данных.
В следующей части разберём, как добавлять стойки и не переборщить с виртуальными нодами. Оставайтесь с нами:)



