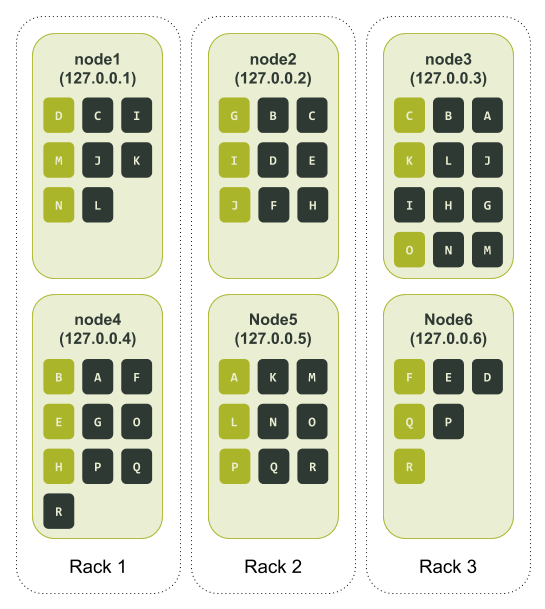
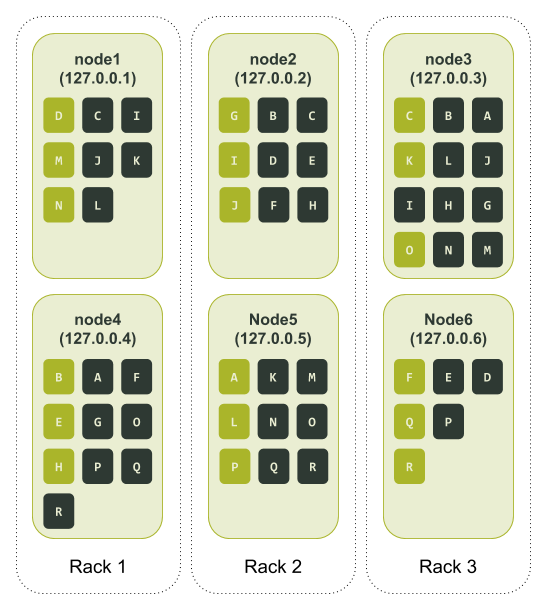
Добавляем стойки
Опытный пользователь Cassandra заметит, что мы тестили распределение токенов в кластерах только в одной стойке. Давайте добавим стойки, чтобы повысить доступность при использовании виртуальных нод. Если стоек несколько, Cassandra попытается распределить реплики по ним, чтобы в одной стойке не было двух одинаковых диапазонов.Надо настроить кластер таким образом, чтобы в одном датацентре число стоек совпадало с коэффициентом репликации.
Возьмем предыдущий пример, где для параметра num_tokens мы выбрали значение 3, только на этот раз определим в тестовом кластере три стойки. Настраиваем и запускаем ноды в ccm. Тестовый кластер выглядит так: https://xpaste.pro/p/Y3uou9TP
Кластер все равно не сбалансирован. Это не так важно. Главное, мы видим, что теперь у нас три стойки и на каждой по две ноды. Снова создаем тестовое keyspace и заполняем его с помощью cqlsh. Смотрим, как распределено кольцо токенов (опять добавляем буквенное обозначение).
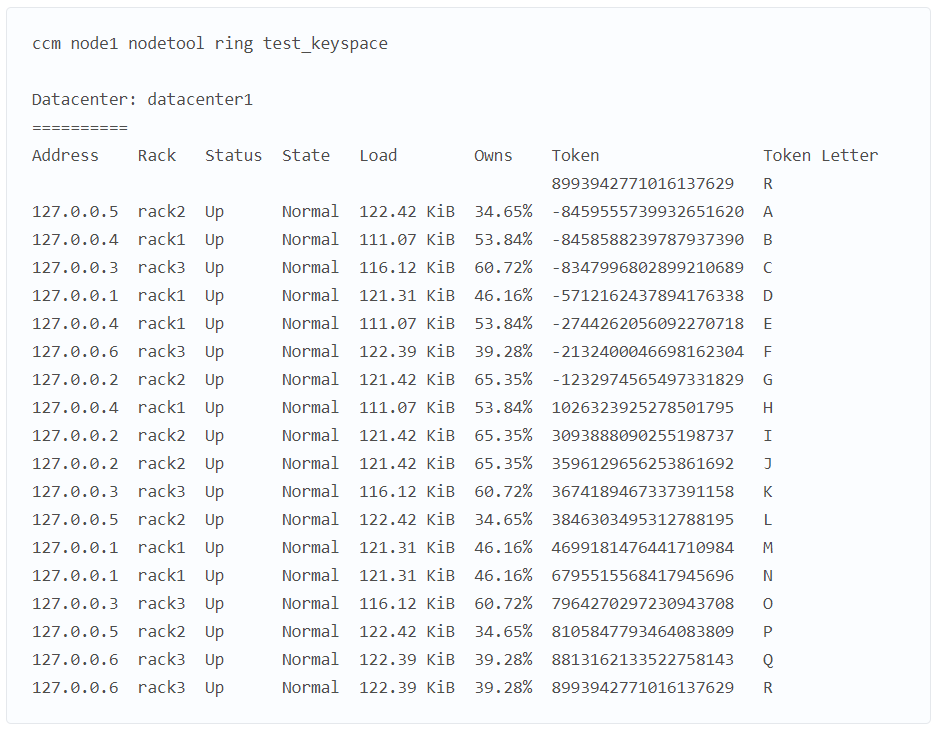
Снова берем выходные данные ccm node1 nodetool describering test_keyspace и меняем номера токенов на буквы.
Посмотреть, как это выглядит: https://xpaste.pro/p/fXWNJQUO
Наконец, смотрим, как диапазоны токенов распределены по нодам:
Судя по назначению токенов, теперь у нас есть полная реплика данных, распределенная по двум узлам в каждой из трех стоек. Если ноды 3 и 6 упадут, мы все равно сможем обслуживать запросы с уровнем согласованности LOCAL_QUORUM. Здесь бросается в глаза нода 3, у которой гораздо больше токенов, чем у других. Ее сосед по стойке, нода 6, наоборот, содержит меньше всего токенов.
Не переборщите с виртуальными нодами
Если при небольшом числе виртуальных нод возникают проблемы распределения, логично предположить, что лучше выбирать число побольше. Но кроме риска потерять доступ к данным при сбое нескольких нод, мы получаем снижение производительности при передаче данных. Чтобы восстановить данные на ноде, Cassandra запускает по одному сеансу восстановления на виртуальную ноду. Сеансы обрабатываются последовательно. Чем больше виртуальных нод, тем больше времени и ресурсов на это уйдет.Чтобы ускорить восстановление при большом количестве виртуальных нод, в версии 3.0 представлено изменение CASSANDRA-5220. Благодаря этому Cassandra объединяет несколько диапазонов для набора нод в один сеанс восстановления. Сеанс выполняется дольше, зато их стало меньше.
Давайте проверим влияние виртуальных нод на восстановление, проведя простой тест на кластере на реальном оборудовании. Для этого создадим кластер с единичным назначением токенов и запустим восстановление. Затем создадим такой же кластер, но с 256 виртуальными нодами, и снова запустим восстановление. Используем tlp-cluster, чтобы создать кластер Cassandra в AWS со следующими свойствами.
- Размер инстанса: i3.2xlarge
- Число нод: 12
- Число стоек: 3 (по 4 ноды на стойку)
- Версия Cassandra: 3.11.9
Команды для сборки кластера: https://xpaste.pro/p/tAQDU6Mk
Выделив оборудование, задаем свойство initial_token для каждой ноды по отдельности. Вычисляем начальные токены для каждой ноды простой командой Python.
Посмотреть, как это выглядит: https://xpaste.pro/p/KVietoOz
После запуска Cassandra на всех нодах можно загрузить около 3 ГБ данных на ноду с помощью команды tlp-stress. В этой команде мы задаем для keyspace коэффициент репликации 3, а для gc_grace_seconds устанавливаем 0. Срок действия хинтов будет истекать сразу после создания, то есть они никогда не попадут на целевую ноду.
Посмотреть, как это выглядит: https://xpaste.pro/p/FM0AEI1V
После загрузки данных статус кластера выглядит так:
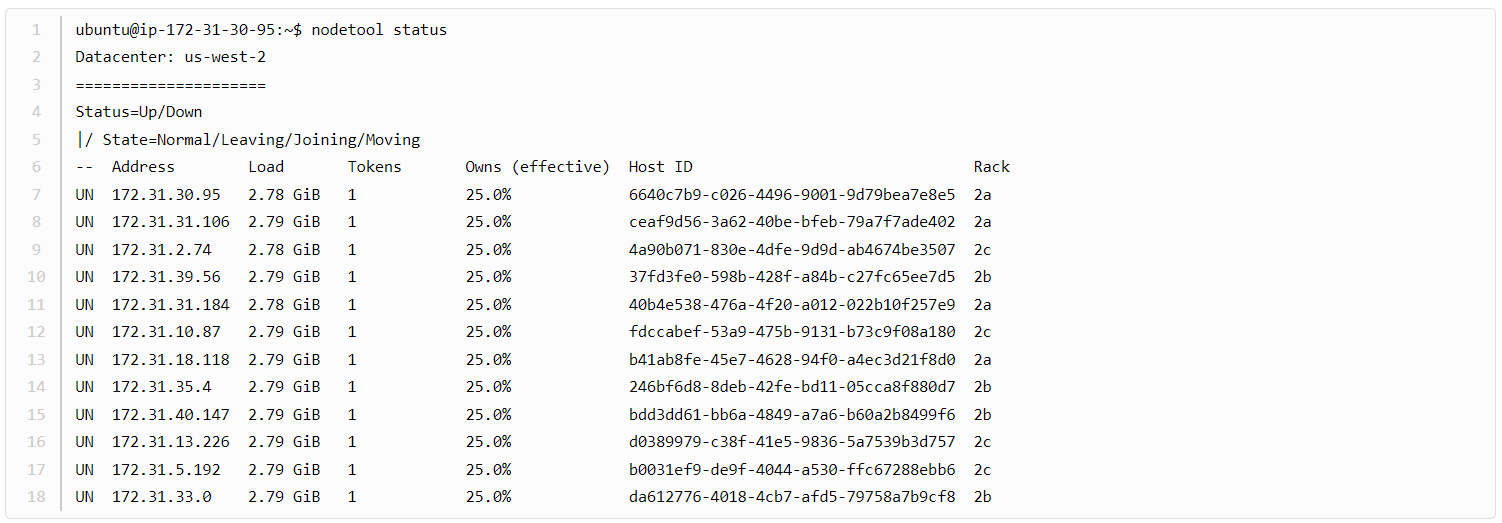
Запускаем полное восстановление на каждой ноде:
$ source env.sh
$ c_all "nodetool repair -full tlp_stress"
Время восстановления для каждой ноды:
[2021-01-22 20:20:13,952] Repair command #1 finished in 3 minutes 55 seconds
[2021-01-22 20:23:57,053] Repair command #1 finished in 3 minutes 36 seconds
[2021-01-22 20:27:42,123] Repair command #1 finished in 3 minutes 32 seconds
[2021-01-22 20:30:57,654] Repair command #1 finished in 3 minutes 21 seconds
[2021-01-22 20:34:27,740] Repair command #1 finished in 3 minutes 17 seconds
[2021-01-22 20:37:40,449] Repair command #1 finished in 3 minutes 23 seconds
[2021-01-22 20:41:32,391] Repair command #1 finished in 3 minutes 36 seconds
[2021-01-22 20:44:52,917] Repair command #1 finished in 3 minutes 25 seconds
[2021-01-22 20:47:57,729] Repair command #1 finished in 2 minutes 58 seconds
[2021-01-22 20:49:58,868] Repair command #1 finished in 1 minute 58 seconds
[2021-01-22 20:51:58,724] Repair command #1 finished in 1 minute 53 seconds
[2021-01-22 20:54:01,100] Repair command #1 finished in 1 minute 50 seconds
Понадобилось 36 минут 44 секунды.
На этом же кластере можно измерить время восстановления, когда используется 256 нод. Делаем следующее.
- Завершаем работу Cassandra на всех нодах.
- Удаляем содержимое каждого каталога data, commitlog, hints и saved_caches (они находятся в /var/lib/cassandra/ на каждой ноде).
- Задаем для параметра num_tokens в файле конфигурации cassandra.yaml значение 256 и удаляем параметр initial_token.
- Запускаем Cassandra на всех нодах.
После заполнения кластера данными статус выглядит так:
Запускаем тот же тест восстановления, что и раньше:
[2021-01-22 22:45:56,689] Repair command #1 finished in 4 minutes 40 seconds
[2021-01-22 22:50:09,170] Repair command #1 finished in 4 minutes 6 seconds
[2021-01-22 22:54:04,820] Repair command #1 finished in 3 minutes 43 seconds
[2021-01-22 22:57:26,193] Repair command #1 finished in 3 minutes 27 seconds
[2021-01-22 23:01:23,554] Repair command #1 finished in 3 minutes 44 seconds
[2021-01-22 23:04:40,523] Repair command #1 finished in 3 minutes 27 seconds
[2021-01-22 23:08:20,231] Repair command #1 finished in 3 minutes 23 seconds
[2021-01-22 23:11:01,230] Repair command #1 finished in 2 minutes 45 seconds
[2021-01-22 23:13:48,682] Repair command #1 finished in 2 minutes 40 seconds
[2021-01-22 23:16:23,630] Repair command #1 finished in 2 minutes 32 seconds
[2021-01-22 23:18:56,786] Repair command #1 finished in 2 minutes 26 seconds
[2021-01-22 23:21:38,961] Repair command #1 finished in 2 minutes 30 seconds
Итого — 39 минут 23 секунды.
Для 3 ГБ данных на ноду разница терпимая (где-то по 45 секунд на ноду), но мы понимаем, что отставание будет существенным, если на каждой ноде будут сотни гигабайт.
К сожалению, такие операции, как инициализация и ребилд датацентра, тоже пострадают от большого числа виртуальных нод. Когда нода передает данные на другую ноду, сеанс передачи открывается для каждого диапазона токенов на ноде. Это приводит к слишком большим издержкам, поскольку данные передаются через JVM.
Проблемы со вторичными индексами
Мало того, большое число виртуальных нод влияет на вторичные индексы. Это связано с тем, как устроен путь чтения.Когда нода-координатор получает от клиента запрос со вторичным индексом, она рассылает его по всем нодам в кластере или датацентре, в зависимости от уровня согласованности. Каждая нода проверяет SSTables для каждого диапазона токенов, назначенного ей, в поисках соответствия этому запросу. Соответствия возвращаются на ноду-координатор.
Поэтому чем больше виртуальных нод, тем медленнее отклик для такого запроса. Более того, ухудшение производительности для вторичных индексов резко возрастает при увеличении числа реплик на кластере. Если в нескольких датацентрах есть ноды, использующие много виртуальных нод, вторичные индексы становятся еще менее эффективными.
Новая надежда
Итак, в Cassandra есть свойство, которое существенно упрощает изменение размера кластера. К сожалению, за это приходится платить несбалансированными диапазонами токенов и снижением производительности операций. Но это еще не вся история.Все уже прекрасно знают, что в Apache Cassandra большое число виртуальных нод имеет побочные эффекты. Чтобы решить эту проблему, изобретательные участники сообщества добавили в версию 3.0 CASSANDRA-7032 — алгоритм распределения токенов, учитывающий реплики, чтобы можно было использовать небольшое значение для num_tokens при сохранении относительно равномерного распределения диапазонов. Сюда входит добавление параметра allocate_tokens_for_keyspace в файл cassandra.yaml. Новый алгоритм используется вместо случайного распределителя токенов. Он назначает существующему пользовательскому keyspace параметр allocate_tokens_for_keyspace.
Cassandra, на основе коэффициента репликации для keyspace, рассчитывает значения токенов для ноды при ее добавлении в кластер. В отличие от случайного генератора токенов, генератор, учитывающий реплики, похож на опытного музыканта симфонического оркестра, играющего в унисон с коллегами. До такой степени, что при генерации диапазонов токенов он:
- Создает начальное состояние кольца токенов.
- Вычисляет кандидатов для новых токенов, разделяя все существующие диапазоны посредине.
- Оценивает ожидаемые улучшения от всех кандидатов, формируя приоритетную очередь.
- Проверяет всех кандидатов в очереди и выбирает лучшую комбинацию.
- Во время выбора токенов пересматривает улучшения кандидатов в очереди.
Для Cassandra это был большой прогресс, но не обошлось и без подводных камней. Во-первых, алгоритм работает только с разметчиком Murmur3Partitioner. Если у вас в кластере используется другой разметчик, например, RandomPartitioner, и вы проапгрейдились до 3.0, эта функция не будет работать. Вторая, более распространенная сложность в том, что для использования этой функции при создании кластера с нуля придется постараться. Есть отдельный пост о том, как использовать новый алгоритм распределения токенов с учетом реплик для настройки нового кластера с равномерным распределением токенов.
Как видите, в Cassandra 3.0 была предпринята честная попытка сгладить острые углы виртуальных нод. В релизе Cassandra 4.0 появились новые улучшения в этой сфере. Например, в файл cassandra.yaml добавлен новый параметр allocate_tokens_for_local_replication_factorчерез CASSANDRA-15260. Как и его двоюродный брат allocate_tokens_for_keyspace, он активирует алгоритм распределения токенов с учетом реплик, если указать для него значение.
Но использовать его гораздо проще и приятнее, потому что с ним создание сбалансированного кластера с нуля не требует столько усилий. В простейшем случае достаточно задать значение для allocate_tokens_for_local_replication_factor, а потом просто добавлять ноды. Продвинутые пользователи все еще могут вручную назначать токены для начальных нод, чтобы сохранить желаемый коэффициент репликации. Последующие ноды можно добавлять со значением коэффициента репликации, назначенным параметру allocate_tokens_for_local_replication_factor.
Пожалуй, самым ожидаемым и важным изменением в Cassandra 4.0 стало изменение дефолтного значения для параметра num_tokens. Как мы уже говорили, благодаря изменению CASSANDRA-13701 в Cassandra 4.0 в файле cassandra.yaml для num_tokens установлено значение 16. Кроме того, параметр allocate_tokens_for_local_replication_factor включен по умолчанию и имеет значение 3.
Эти дефолтные параметры гораздо лучше. В ванильной установке Cassandra 4.0 алгоритм распределения токенов с учетом реплик начинает работать, как только появляется достаточно хостов, чтобы соблюсти коэффициент репликации 3. В результате имеем равномерное распределение диапазонов токенов для новых нод со всеми преимуществами, которое дает малое число виртуальных нод.



